


I figured it was too much overclocking on some of my gpus
Update:
My main rig’s issue was not related to 10+ GPUs. I removed 6 GPUs, and then re-installed the 2 orginal GPUs I had removed and the error messages began again. Seems to be a defective riser part.
I suppose the problem is with the nvidia driver or the nvidia-settings command.
From here:
it looks like nvidia-settings commands fails somehow, which causes the autofan error message.
There is no recovery attempted in the code except a reboot when REBOOT_ON_ERROR is set.
When the error happens I do see that nvidia-settings process is sitting there taking up 100% CPU. The system load goes up to 15. Sometimes (not always) killing this proc and restarting the miner does the trick. If used -9 it most likely will warrant a reboot.
I suggest to try restarting the X server and re-trying nvidia-settings command again. Maybe rmmod/insmod nvidia drivers? And only then reboot? I don’t know.
If somebody has time to look at what exactly is failing with nvidia-settings, we could figure something out.
Change this line:
timeout 60 nvidia-settings $args > /dev/null 2>&1
to:
timeout 60 nvidia-settings $args | tee /tmp/nvidia-settings.out 2>&1
and try to catch the error in the output?
Be aware not to fill up /tmp or /
thanks,
-alexm
после апгрейда с 0.5-57 до последней стало появляться Autofan: GPU driver error, no temps и все висит пока не сделаешь reboot
пришлось откатиться обратно до 0.5-57
пожалуйста поправьте в последних версиях это
I am a paying member, CAN WE PLEASE GET A RESPONSE ON THIS.
How do we fix it? I don’t like my rigs not working. I dont want to go reinstall windows on my rigs.
What is the solution?
i am using 5.69 the latest version.
In Hive 2 autofan script does not reboot rig by default. It can give some warnings about failed temerature reads or driver error but will not reboot if you didn’t enable it.
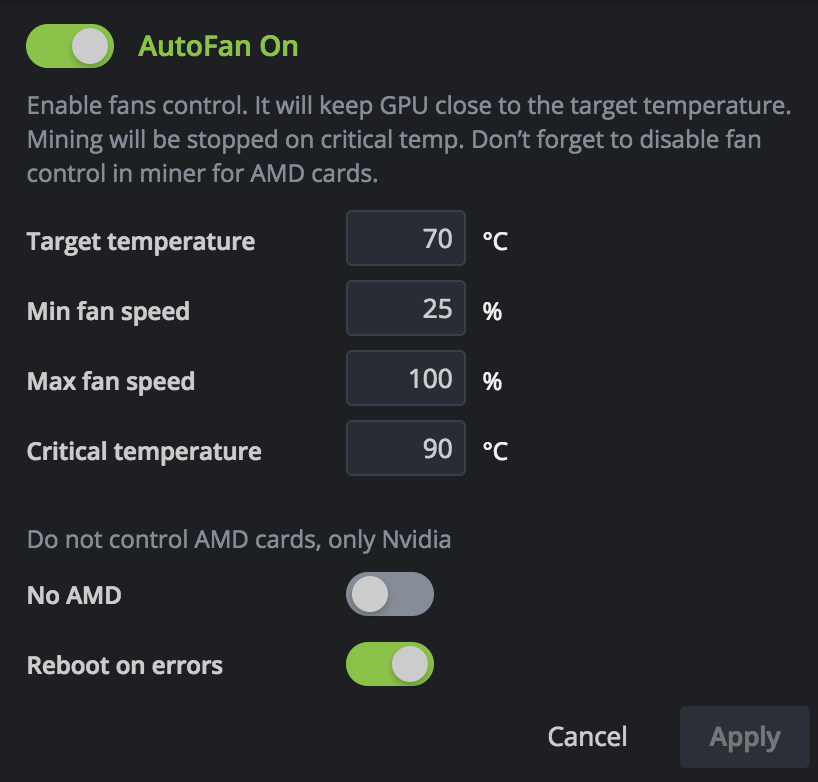
Dear developer, what will happen if I switch off “reboot on errors”? It doesn’t fix anything, and how the system will know the proper speed for cards? Just 100%?
Уважаемый разработчик, так а что произойдёт, если я выключу “reboot on errors”? Ошибки то это не исправит! И какую скорость автофона в таком случае выставит Хайв, на 100% просто?
1 Like
Дико раздражает, каждые 5-30 минут риг идёт в перезагрузку с ошибкой «Autofan: GPU driver error, rebooting» как это пофиксить? Или какие настройки корректные сделать?
Сейчас
задано : Целевая температура 65
Минимальная скорость 25
максимальная скорость 100
Критичная температура 79
Перезагрузка при ошибках - вкл.
Тоже столкнулся с этой неприятной проблемой, много часов ушло на ее решение, до конца решить пока не удалось, но есть гипотезы в чем причина. Последние обновления хайва не тянули за собой обновления драйверов nvidia, в частности обновив hiveos на нескольких машинах до 0.5-70, я заметил, что драйвера nvidia остались прежними - 387.34, хотя последние стабильные драйвера 390.59
Пробовал обновлять вручную через скрипт “nvidia-driver-update”, но получил ошибку:
ERROR: An NVIDIA kernel module ‘nvidia-modeset’ appears to already be
loaded in your kernel. This may be because it is in use (for
example, by an X server, a CUDA program, or the NVIDIA Persistence
Daemon), but this may also happen if your kernel was configured
without support for module unloading. Please be sure to exit any
programs that may be using the GPU(s) before attempting to upgrade
your driver. If no GPU-based programs are running, you know that
your kernel supports module unloading, and you still receive this
message, then an error may have occured that has corrupted an NVIDIA
kernel module’s usage count, for which the simplest remedy is to
reboot your computer.ERROR: Installation has failed. Please see the file '/var/log/nvidia-installer.log' for details. You may find suggestions on fixing installation problems in the README available on the Linux driver download page at www.nvidia.com.
I have the same problem every 2 or 3 months at some rigs.
the solution is cleaning all the components on the rigs and install VGA one by one.
and usually all back to normal.
I also found A broken power supply cable and broken riser is one of the causes of the problem.
Terima Kasih
2 Likes
What causes autofan to fail is this:
/hive/sbin/autofan: line 350: 21712 Segmentation fault timeout -s9 60 nvidia-settings $args > /dev/null 2>&1
When i run nvidia-settings, even without any parameters, it stops with segmentation fault. No other messages, no other information.
Autofan does not work, gpu-fans-find does not work (same segmentation fault), fan speed settings do not work.
1 Like
Вчера запустил ферму, часов 6 работало норм, под утро начало вырубать:
autofan.conf didn’t exist, so I created it with the following data,
Claymore Reboot WATCHDOG GPU 2 hangs in OpenCL call, exit.
Перепробовал все советы, дрова стояли 39*.* - не помню точно, но по совету выше решил обновить дрова NVIDIA через =Shellinabox=. Актуальная версия: 410.66. Заодно майнер поменял на =ethermine= - час полёт норм!!
1 Like
hi all… i have big problem in my ring…
the ring have restart all the time for this error
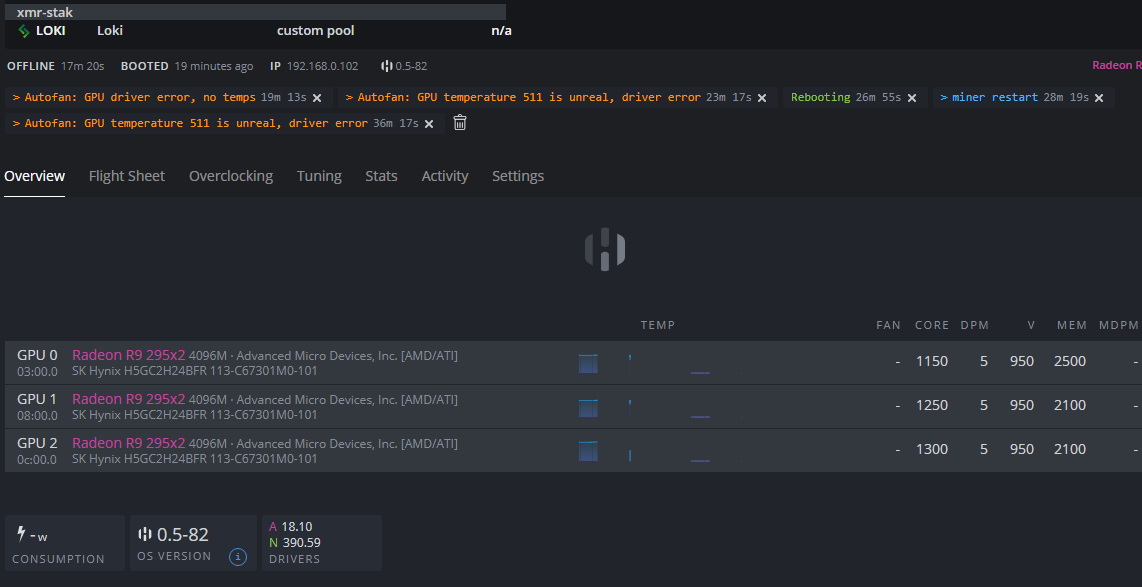
i dont have nvndia card… i have amd cards…
error
[/code]
{ “temp” : [ “” ] , “fan” : [ “” ] , “load” : [ “” ] , “power” : [ “” ] , “busids” : [ “” ] , “brand” : [ “” ] }
[/code]
error
>Autofan: GPU temperature 511 is unreal, driver error
**{** **"temp"** **:** **[** "45" **,** "42" **,** "511" **,** "511" **,** "511" **,** "511" ****]**** **,** **"fan"** **:** **[** "0" **,** "0" **,** "0" **,** "0" **,** "0" **,** "0" ****]**** **,** **"load"** **:** **[** "0" **,** "0" **,** "0" **,** "0" **,** "0" **,** "0" ****]**** **,** **"power"** **:** **[** "" **,** "" **,** "" **,** "" **,** "" **,** "" ****]**** **,** **"busids"** **:** **[** "03:00.0" **,** "04:00.0" **,** "08:00.0" **,** "09:00.0" **,** "0c:00.0" **,** "0d:00.0" ****]**** **,** **"brand"** **:** **[** "amd" **,** "amd" **,** "amd" **,** "amd" **,** "amd" **,** "amd" ****]**** ****}****how to fix error
we try to do what our friend TwoChiefs says
to go here nano /hive-config/autofan.conf
i put here
# Set to 1 to disable AMD fan control
NO_AMD=1but the error is displayed again and again…
makes a restart ring and stops doing mining
please tell me what I can do
Same problem here. I only have 4 GPUs though. I always suspected the risers, but the guy i’m buying the risers from said his clients never have had problems with his risers. I’ve tried 6 different risers per GPU. It can’t be that they’re all defective…
Is there any way to detect which GPU temp readings failed exactly? That way I could at least narrow down the problem.
everyone tells me that this is because I’ve been doing overclocking in fact I have not done any overclock is as it regulates the xmr
Solution:
apt update
apt-get install --reinstall -y nvidia-settings
1 Like
Did this worked?
hi i have same prolem,are u fix ur rig yet please let me know
1 Like
en el caso de tener AMD, sería: apt apt-get install --reinstall -y amd-settings ???
esto reinstala los drivers?
same error here.
can’t get temperature for GPU #0, error code 15, any advice ???
RTX 3060 LHR
T_rex
Hiveos last version
Drivers NVidia: 470.86