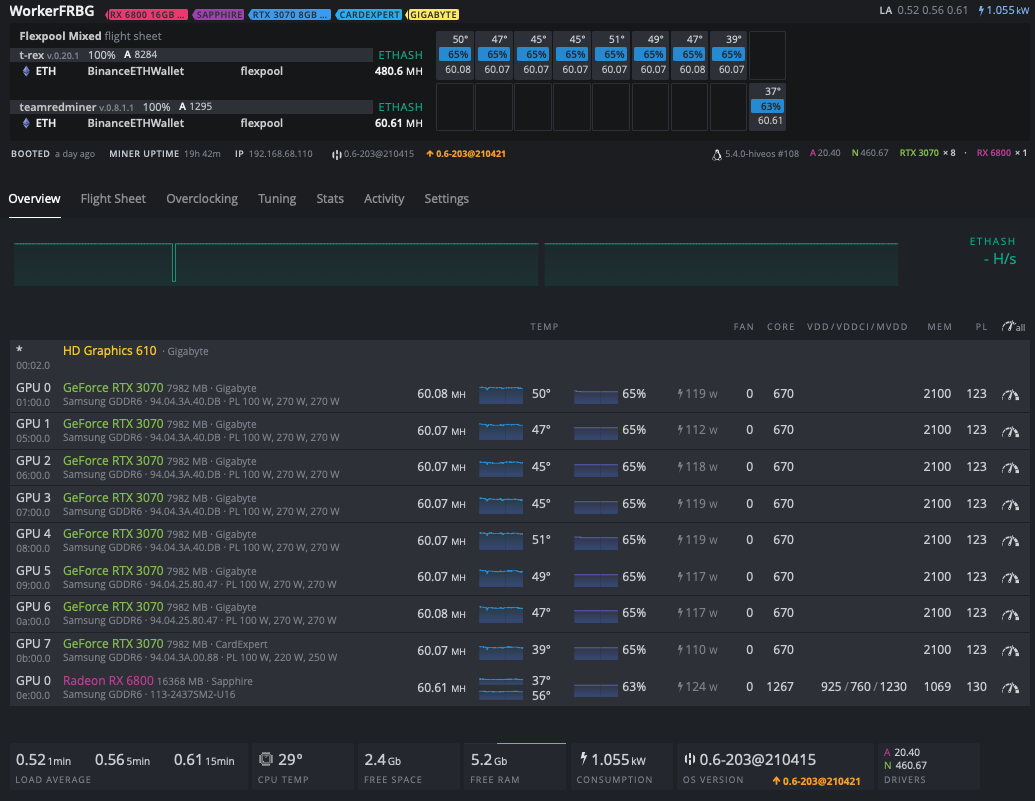
I’m experiencing difficulties setting this way so I tried the 670 directly on the GUI and it looks fine, I’m getting the better efficiency I could see until now (besides less 2Mh/s on performance).
Personally, I’d go for an extra 2Mh. You are losing 14Mh overall.
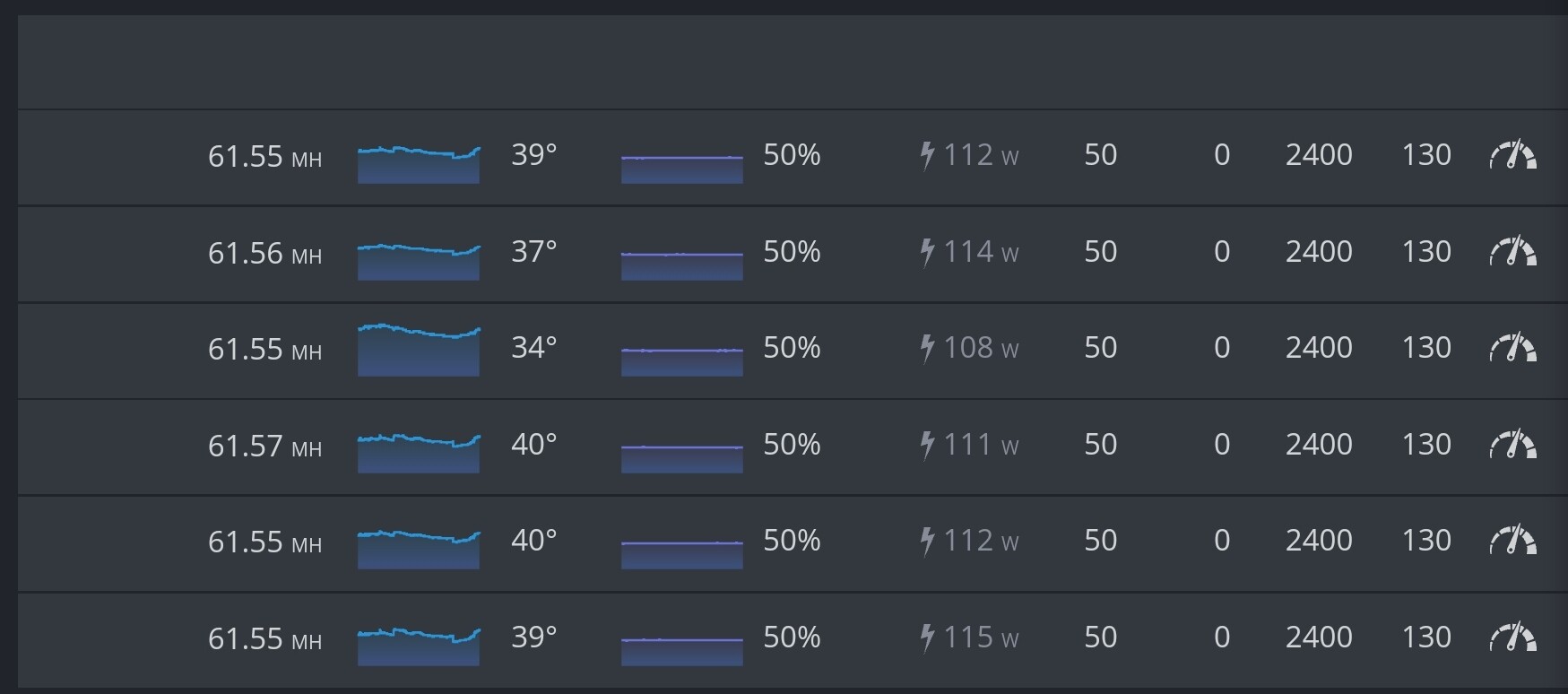
I’ve settled on -400, lgc 670 for my 3070s. Hashing well so far on 2550 MEM
Also I’ve put nvidia-smi commands in a script and set it as start script in T-rex with “script-start”:"/home/user/set-gpu-clock.sh"
Now it sets gpu clocks automatically every time I restart miner or reboot the rig and I don’t have to bother doing it manually.
Effective GPU clocks = lgc value - offset value
In you first case Effective clocks = 750 - (-500) = 1250MHz, which is too much for 3070 and too low for 3060ti. For 3070 you shold aquire better results around 1080MHz effective GPU clock and for 3060ti - around 1425. But every silicon is different so YMMV.
When you enter 750 in GUI your offset =0, so
effective clock = 750 - 0 = 750 Mhz, hence lower hashrate.
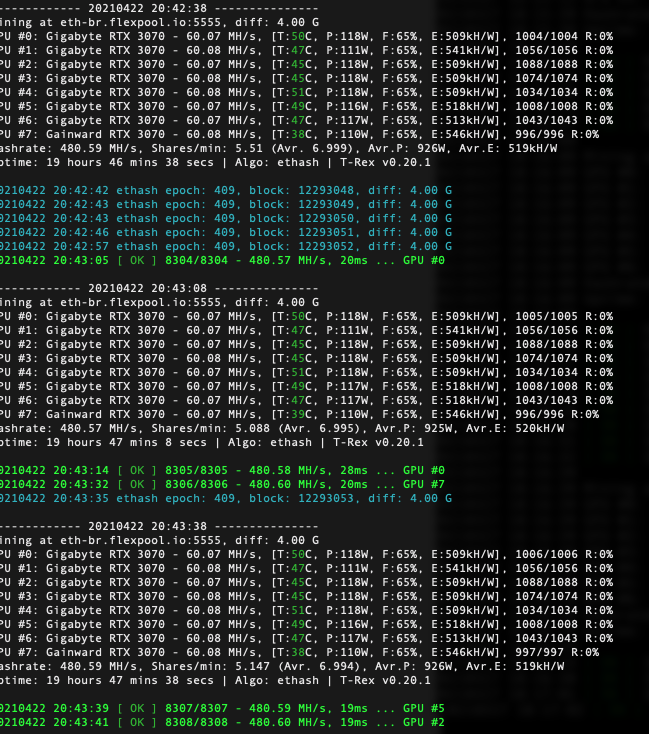
It is strange, but setting offset -400 and lgc 680 gives 3-5W lower power consumption and the same hashrate compared to offset 0 and lgc 1080 (entering 1080 directly in the gui).
I’m suspecting that software wattmeter could be not correct in that specific case. I plan to test it with hardware wattmeter. It could be there is no difference in real power consumpion. Will check that theory when I get my hardware Kill-a-watt.
Thanks for deep answer
Yap, it seems there is difference in set gpu clock in one step or in 2 steps (gui + after cli)
I’ll test 1080MHz in gui vs -500 gui at boot and 750 cli
or… eg -500 gui and after 1080MHz in gui too
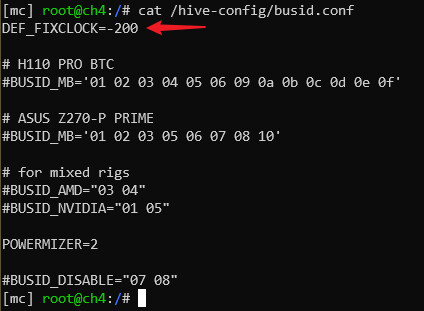
BTW seems that I can set only the same value for all cards. Is it possible to set different value for each card that way? Tried comma and space separated list, but no luck.
UPD: Nevermind. Figured it out. Had to modify nvidia-oc script a bit. Now it accepts array of values in DEF_FIXCLOCK.
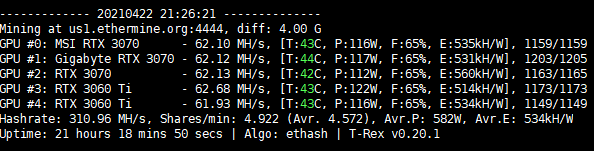
After more than 50 days of trial , jumping from windows to hiveos
I was thinking that I found the right OC for my 9x RTX 3070
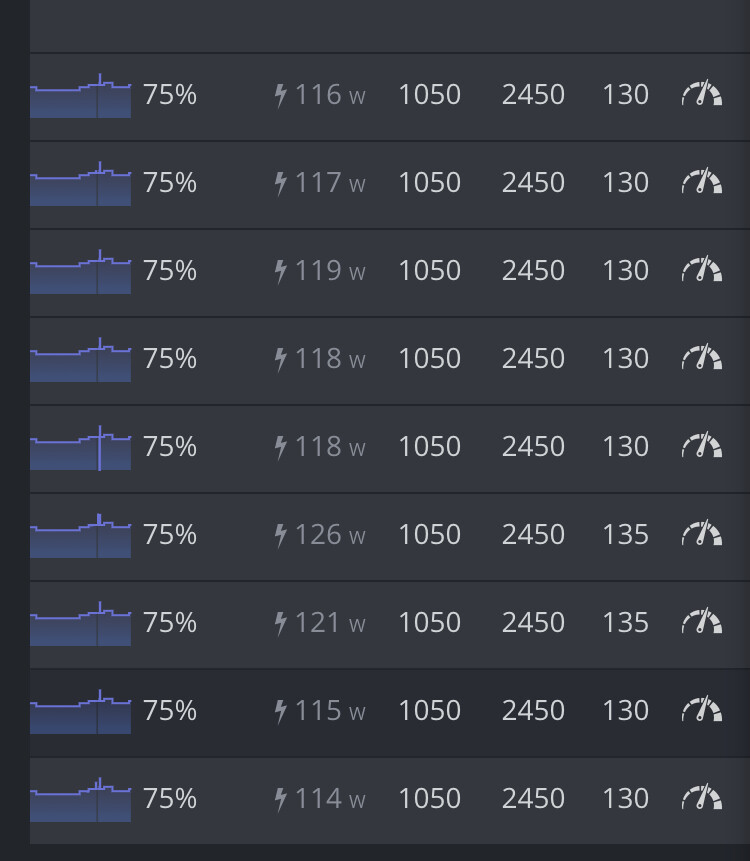
Absolute Core Clock 1100
Memory Clock 2600
PL 130w (I have 1 thirsty msi 2x ventus and a pny xlr8 which are set to 135W)
Delay in applying oc 60sec
I use AsRock H110BTC
2x Corsair 1200W platinum
Riser feed via 6pin …etc
T-rex miner.
All works well with no rejected shares
but the miner decides to restart after ~6h (max managed of 17h)
When I check the logs in shell tells my CUDA ERROR…lower oc … which I did… I left them at 1070 which worked for 14h, no issues after that… miner restart again.
Now I will trial the ss below …
What am I doing wrong…?