I need your help!
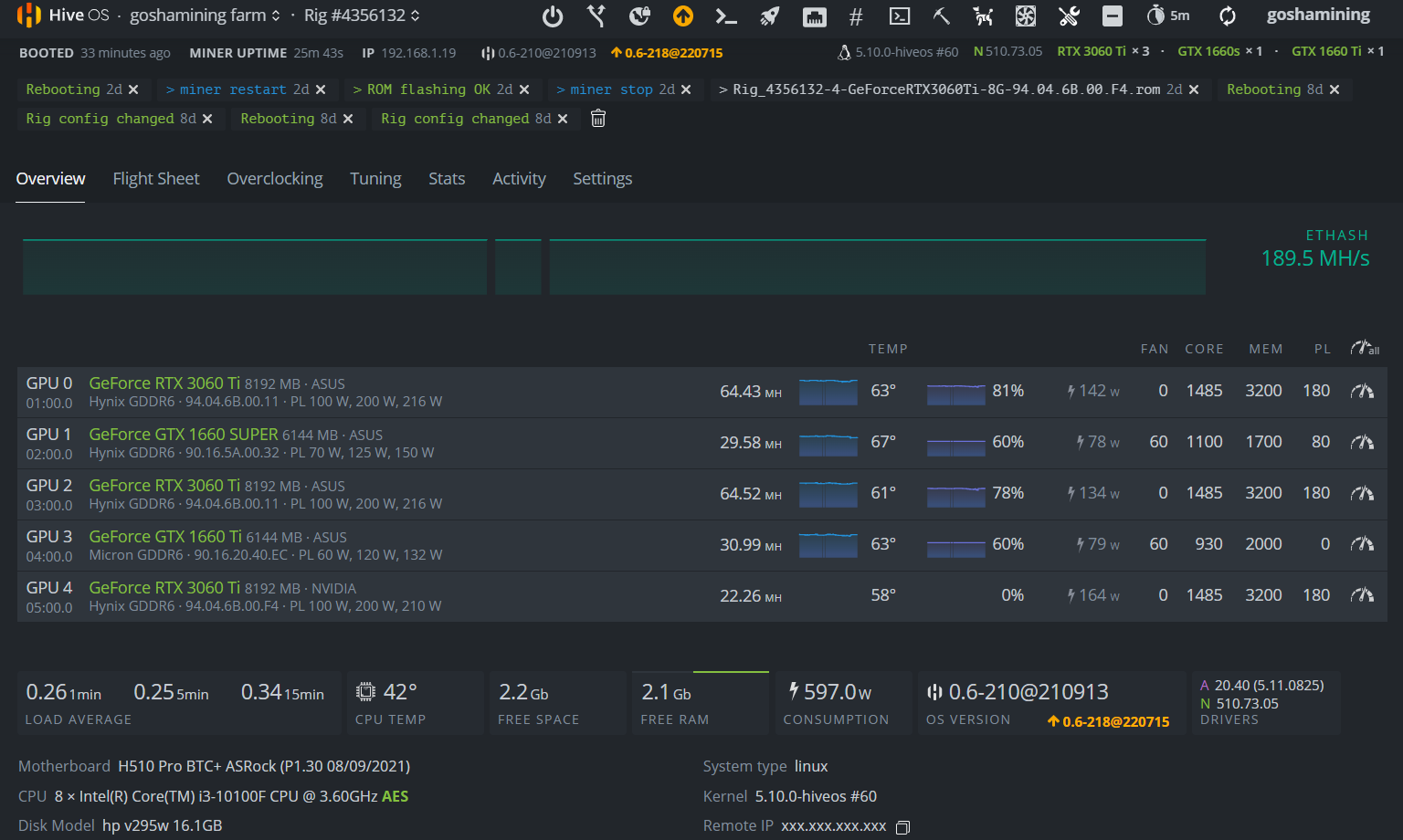
I have 3 3060ti cards but the last one (gpu4) started to “fail” for a few days now:
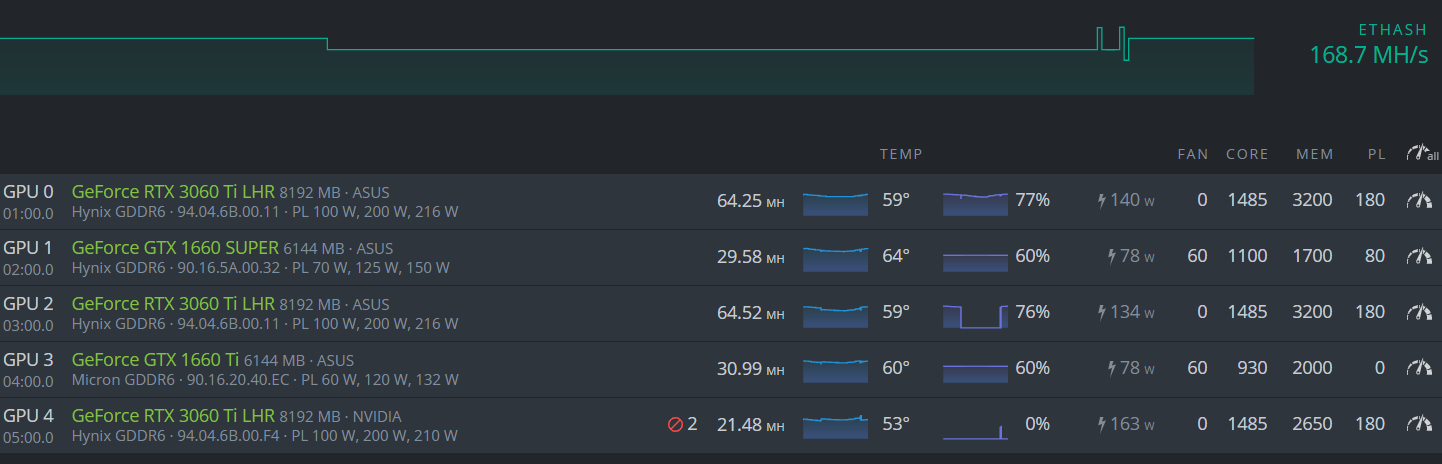
The last card is a little over 3 months old and I have always used the same configuration on the 3 3060ti without any problems, until a few days ago. When the rig starts the first minute all normal (64mh average), after the minute it goes down to 22mh.
The error that hiveos says is “error loading LHR”
I already tried many different overlocks without any success.
I already changed the Bios (if you know of a better bios please tell me)
Drivers updated to the latest
Hiveos already updated it to the latest and I already downgraded it to the basics. (that is, I have tried everything, please don’t tell me that the solution is to update hiveos because no, it is not there)
Just in case, check the thermal paste and change it too (deep cleaning included)
And the problem persists. Please I need help, I don’t know what else to do.
I have applied this technique, and it works for a short time, sometimes up to two days in a row.
When I have reduced the mem clock a lot it starts to give a lot of errors, so I increase the value again and start the process of reducing it from 50 to 50 and letting it stabilize.
But the problem always persists, is there any way or configuration to make it fixed?
Reducing the mem clock won’t cause more errors. Just reduce any time you have a error or crash or when the fan percentage shows as 0 and reboot. Repeat until it is stable
its not a once and done adjustment. reduce each time you have an error or crash, continue reducing until its stable. are you at 0 on the memory already?
If you are still running a kernel, and HiveOS miner version from 2021 expecting LHR unlocking to perform optimally, I recommend an upgrade to where most folks are today.
Suggest upgrading the kernel via a shell interface:
Believe me I do it, I go down until I reach the right point… it lasts a few hours and fails again, I keep going down and so on…
The problem is that when I download a lot on card 4, for some reason it also affects the other 2 3060Ti cards and hiveon fails (it unconfigures) and I have to reinstall everything from 0 (operating system), so I learned that I don’t have to lower than 2200 otherwise it causes a problem in the operating system.
that doesnt make sense to me. lowering the memory wont do anything but make it more stable. anytime the driver crashes a reboot should be all thats needed. but as Grea said, flash the latest stable image first , then reduce oc as they crash and repeat until its stable.
I don’t know if you had the opportunity to read, but I had already explained this:
" * Hiveos already updated it to the latest and I already downgraded it to the basics. (that is, I have tried everything, please don’t tell me that the solution is to update hiveos because no, it is not there)"
I already tried everything…
What works for me temporarily is to lower the memory clock. It lasts a few hours and then crashes again.
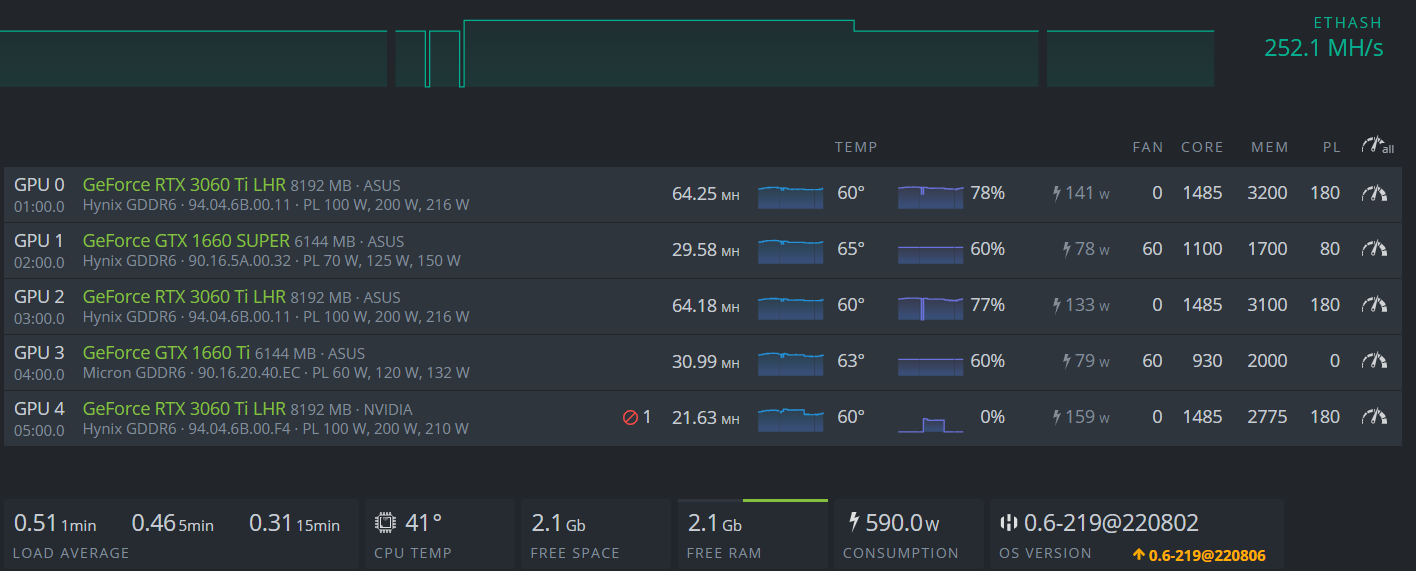
memory on your crashing gpu at 2775 (thats pretty aggressive, i have many cards that wont run at all at that) doesnt look like youve been actively lowering the memory each crash. try the memory at 1000 and see if its stable if you are unable to lower each crash.
your original screenshot shows youre on kernel #60, aka a beta image from august 2021. did you flash the latest stable since? please show the kernel youre currently on to be sure.
I updated to latest didnt check anything and bang failed
so i had a little trouble getting back old driver but now i dont know what im using
not touched vbios either
GPU 0
10:00.0 GeForce RTX 3060 Ti LHR 8192 MB · Gigabyte