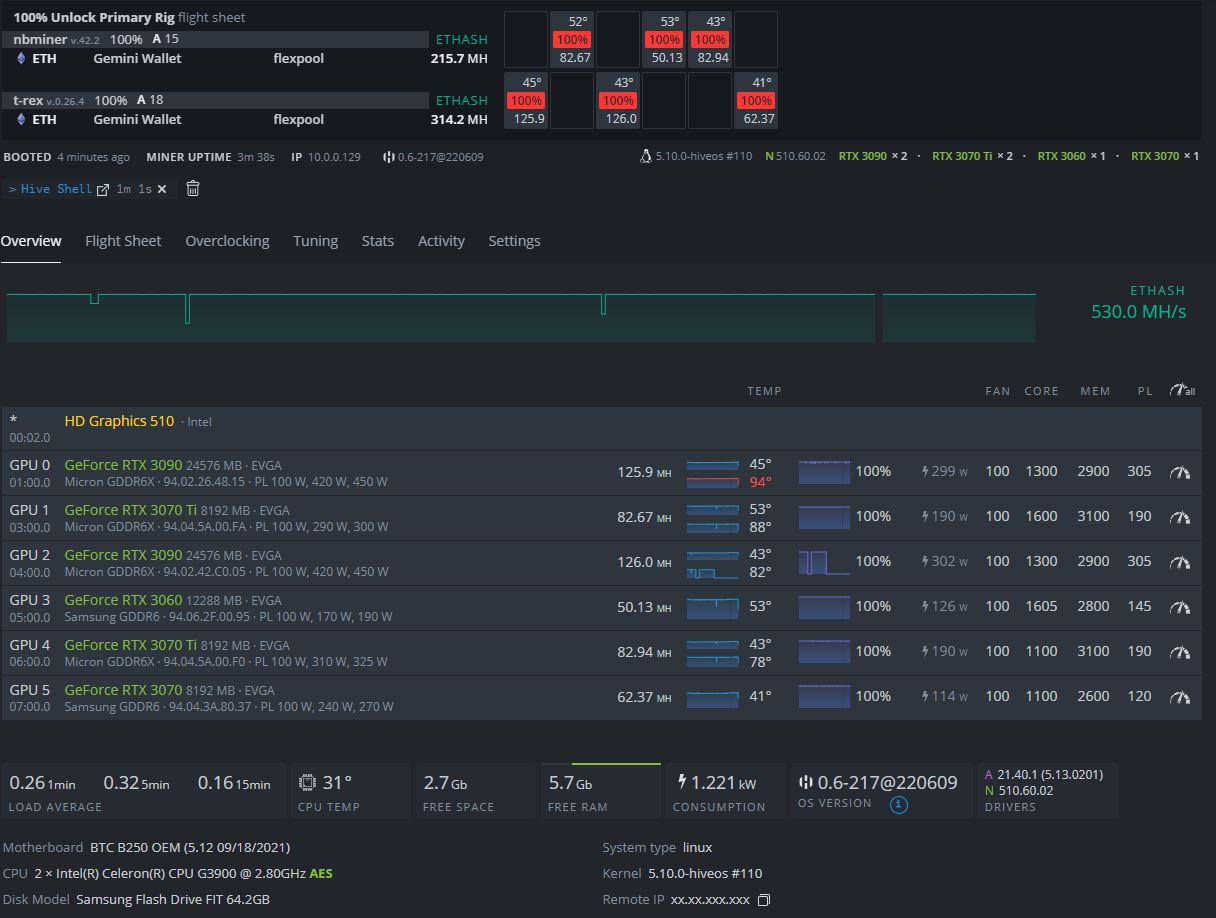
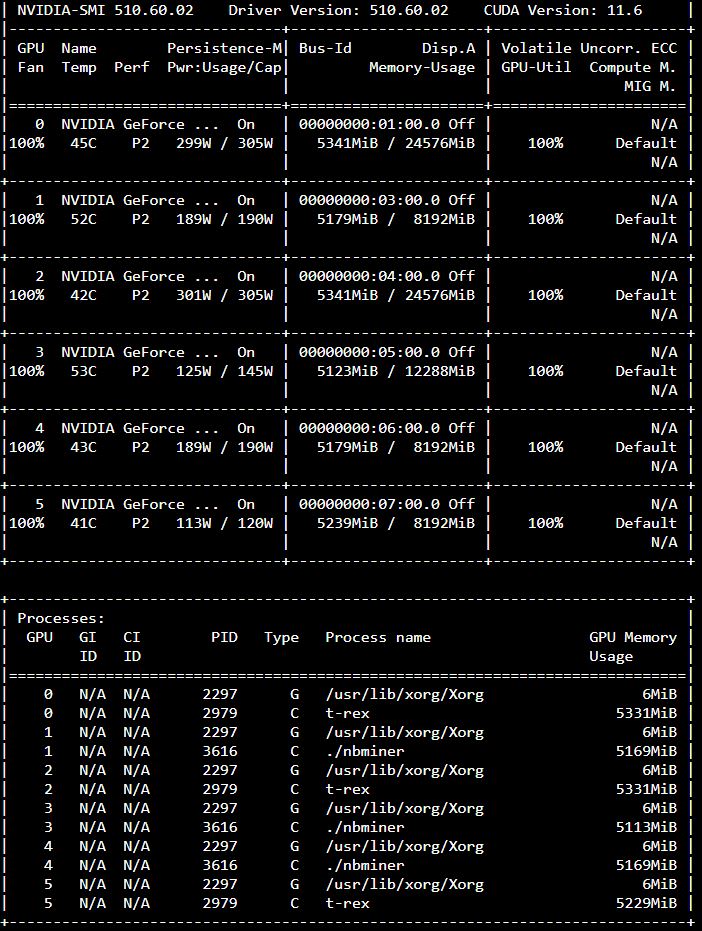
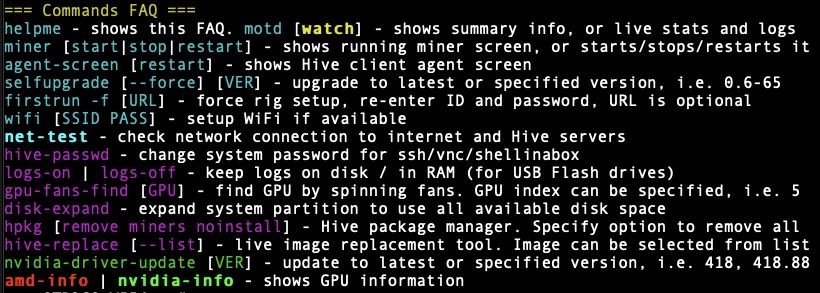
Thank you. Youve been the most helpful so far. For updating the kernel is there a way I can do that from the terminal or do I have to force a reflash of the usb?
Edit: I have found the command to update version and kernel, I am now on version 110.
I can look into using an nvme / m.2 drive as I have a few spare but theyre all 512GB or 1TB and that feels like it would be a waste. I can look into getting 128GB nvme ssds though. However, you would be correct that this board has no nvme slot. (ver 1.1 does but 1.0 and 1.2 do not.) I have been running USB on all of my rigs with only one instance ( and already older usb ) dying after a power outage. I can look into using a standard SATA SSD as I do have a few 128 or 256 GB instances laying around but I havent used those as they cost more power than a USB.
I can easily run disk expand. Where can I enable logging?
I’ll look more into rebtech and hold off for now then. I’ll also look into a TB 360 Pro 2 or H110. Is there anywhere specific you recommend I get one of those boards from? Do these boards all have a limitation of Nvidia GPUs needing to be only the first 6-8 slots? I recall seeing some blueprints showing that PCIe slots 6-11 do not fully fupport nvidia gpus on the btc b250 pcie version.
I wanted to downsize rig amount to mitigate both HiveOS and electrical costs but I’ve also seen more information about people sticking to 6-8 GPU systems and eating the costs for general stability.
Congrats on getting it running on latest kernel :slight_smile, HiveOS, and most of your miner versions as well. I am confused on your miner selection, but we all have a strategy.
NVME drives will burn a PCI address, so be choosy on your motherboard choices vs. using old school SATA.
You really don’t want to run logs on a USB drive, the write speed is not your friend as it is, but here are the commands (logs-on) from hiveshell, shellinabox, or PuTTY:
My 12 GPU rigs are only built with very stable GPUs or there are too many chances for misbehaving cards creating issues and taking a large rig down.
I move the diva/complainer types to 8 GPUs or even far less as needed and tend to group them with other similar overclocking performers, etc. As the trouble increases, the power increases and the clocks go down. During high temp and low profit times, I shut off the worst performers.
Gotcha, I can look into reusing an old hard drive or ssd over SATA and enable logging on that, especially once I have this runing a full 12 GPU system I’m probably going to want that.
I’m open to miner suggestions. I’ve been using nbminer since it was one of the first with the LHR limit remover. TRex miner was recommended by a friendd since its seemingly an Nvidia specific miner. I have been keeping LHR and non LHR cards separate to avoid any issues.
I’ve been running these GPUs each for months now since I started mining. This was my first rig and I’ve just been trying to shift it to this other board. My hope is to eventually condense to a 12 GPU systems for my stable cards in order to save on some power and HiveOS costs.
So far, no issues since updating Kernel either. As mentioned before the only other differences is using 0-5 PCIE USB lanes and keeping the on-board graphics active by having the monitor plugged in to live monitor it for whenever it crashes (if it’s going to again). Perhaps one of these was the main fix, but I won’t know until I start testing without a monitor plugged in and/or testing with more than 6 GPUs if one of the PCIE lanes is bad.
Thank you again so much for your help. I’ll keep this forum updated as it has the most documentation and troubleshooting regarding this known issue with the BTC B250C boards.
for miner recommendations i personally run lolminer on all my nvidia and teamredmier for all my amd, mining eth+ ton on all but that only has a week left or so. lolminer has the lowest dev fee of the lhr unlocker miners at .7%
I already use TeamRedMiner for my AMD cards on a separate rig.
Is lolminer able to run LHR and non LHR cards simultaneously and still properly unlock LHR cards without conflict?
Why is ETH + TON only lasting a week? I used to mine ETH + TON but stopped after LHR limiters were removed to not limit my ETH rates and reduce electric / heat.
You should always have a reserve rig which is up to date, 100% functional, and can be used for testing 1 or 2 GPUs the act up, require thermal pad changes, etc. You don’t want to test things in a big rig. Such test actions, can be done on Hiveon Pools for no cost and with the new adjustable payout options, no long term losses. Even when billed, they bill in less than daily increments and less than $0.10/day.
You may find the board you are working with now, goes into test bench mode and only utilizes the clearly marked ports that work.
Yeah I’ve been using that previously mentioned AMD rig to test any time I get a new GPU typically as it’s not a full rig. That rig is already running kernel 110 (which I didn’t even realize until going and checking / upgrading all rigs after yesterday) and latest nvidia driver. My plan was once I had a condensed rig that I’d repurpose one of the boards and old frames as a proper test bench.
I’d also appreciate your recommendation on nvidia miner. At this point I may switch to lolminer or use lolminer for lhr and nbminer for non lhr. Unless both can be run on one now.
I can count my nVidia GPUs on the fingers of both hands vs. a materially larger amount of AMD GPUs. With the level of bias toward AMD I am:
100% Team Red Miner for AMD
100% T-Rex for nVidia (you can see 100% unlocking and non-LHR detected above)
I’ll pay the extra dev fee to be able to log miner errors clearly between the two very different power tables, etc.
Full disclosure: I expect the future of mining to force me to rethink my approach as various miners add various new algos. Who knows what we’ll be doing in a few months
I do expect I’ll be running multiple miners in my rigs for flexibility.
Yeah I’ll look into either using lolminer for cheapest and/or trex to reduce total miner count and extra logging/stats like you’ve mentioned.
I do appreciate AMD for the lower power consumption and may look into picking up another 5700XT or two for RR mode.
Next time I respond will be back on topic with either the board having crashed again or stating that Im past 72 hours. (The longest period I’ve seen recorded online of a b250c running before the error occurs.)
Still thinking that, assuming it is fixed now, it may have been that ports 0-5 need to be used first or that the on board graphics / hdmi need to be kept occupied. Could also have been the older HiveOS kernel. All good things for any future individuals facing this issue to try as solutions.
Running a very wide mix of motherboards here, Kernel #83 did not have stability issues, most of my rigs were running 30+ days until I shut them down for maintenance, fan cleaning, etc.
The OS either runs, or it doesn’t. Power, heat, hardware, miners, and settings are the issue for a running rig.
Side note: Did you see this, definitely dig into your R mode particulars, deeply:
The rig has now been running 24 hours without issue so far. However, people have reported the weird issue of this motherboard losing connection to mining systems but remaining in an on state (ethernet lights flash, gpus run, etc) can take up to 70 hours before it occurs. One day down and two to go essentially.
I do not currently have the amd gpus running on a BTC B250 based board and do not plan to, I do not have enough to warrant running them on a 12 GPU board. However, I will keep that setting in mind.
I also looked into Rebtech and you’re correct, they are now only recommended for AMD rigs as they do not support the latest Nvidia drivers.
I have since proceeded to combine my second rig with this rig. I am currently running 10-11 GPUs on the board. I encountered some minor, unrelated issues (Nvidia Driver error 45 and 62, these being “not enough power” and “overheating” respectfully). The combined rig is coming up on 24 hours of running and has not had issues (besides initial setup ones mentioned).
I have also learned more about HiveOS watchdog and properly enabled that for when LA gets above 5 (instead of the default 25) or when hashrate drops signaicantly below standard.
Back to the main topic, here is a list of all major differences between when the board would encounter the blue screen / connection loss issue and it now being in a seemingly stable state. I am hoping that anyone who encounters this known issue witht he board will be able to fix it after trying these.
Updating to HiveOS Kernel 110 (try latest version and kernel for any system if this connection loss / blanking out error is occurring)
Keeping a cable or dongle in the HDMI port thus keeping the on-board graphics active
Ensuring that the first six slots labelled 0-5 (or labelled PCIE 0-2, USB groups of 2) are used first.
Re-seeding the motherboard and CPU power connectors (using the right-side half of the CPU connector this time)
As an additional note my overclocks are the same however I did reduce some of their core clocks as I was able to get the same hashrates with lower clock and a small decrease in temaptrues.
Special thanks to Grea as you have been the largest help here and allowed me to learn more about both HiveOS and mining than the original problem entailed.
If the problem happens again I’ll make a post but for now, Im signing out.