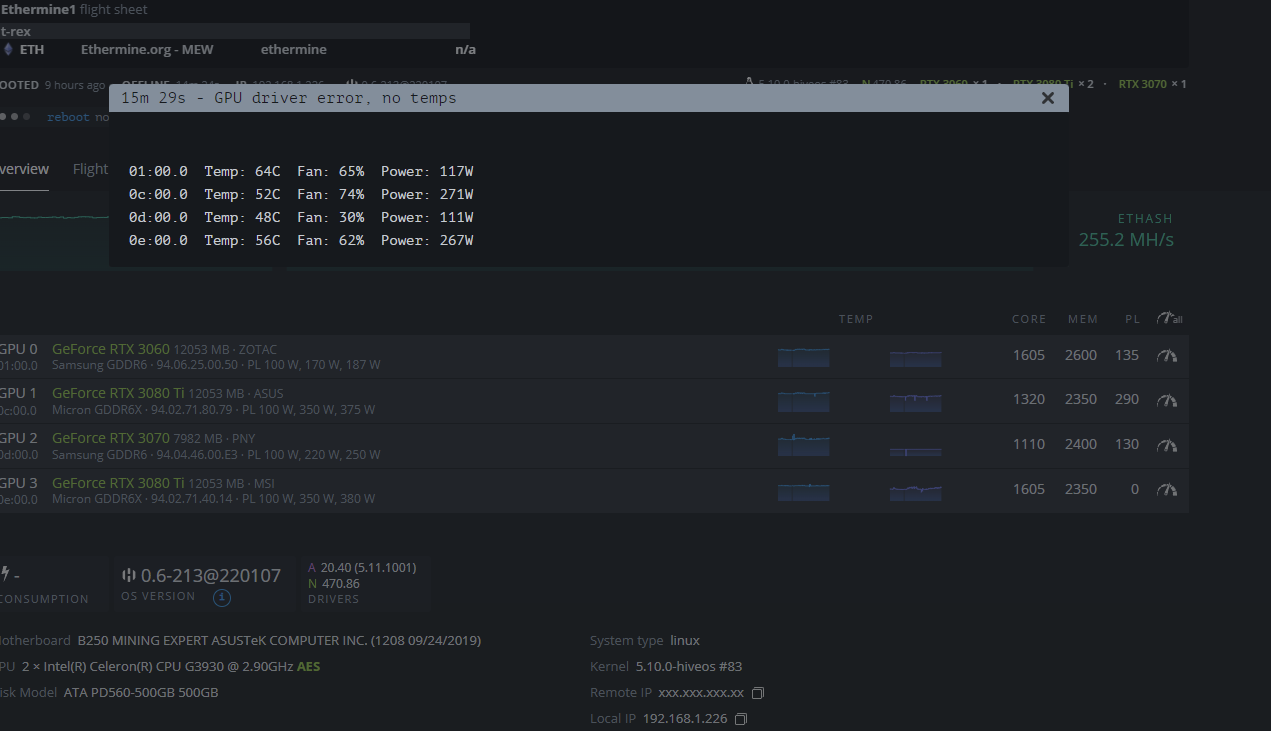
I have one of my rigs reboot probably about once every two days due to “GPU driver error, no temps”. When I click on the error though, I see the following with no additional information. I understand from other posts that this could be the memory overclock on one of the cards, or a power delivery issue, or even ghost settings (needing a re-image of the drive). I’d like to figure out which card this is though. Is there a way to do that.
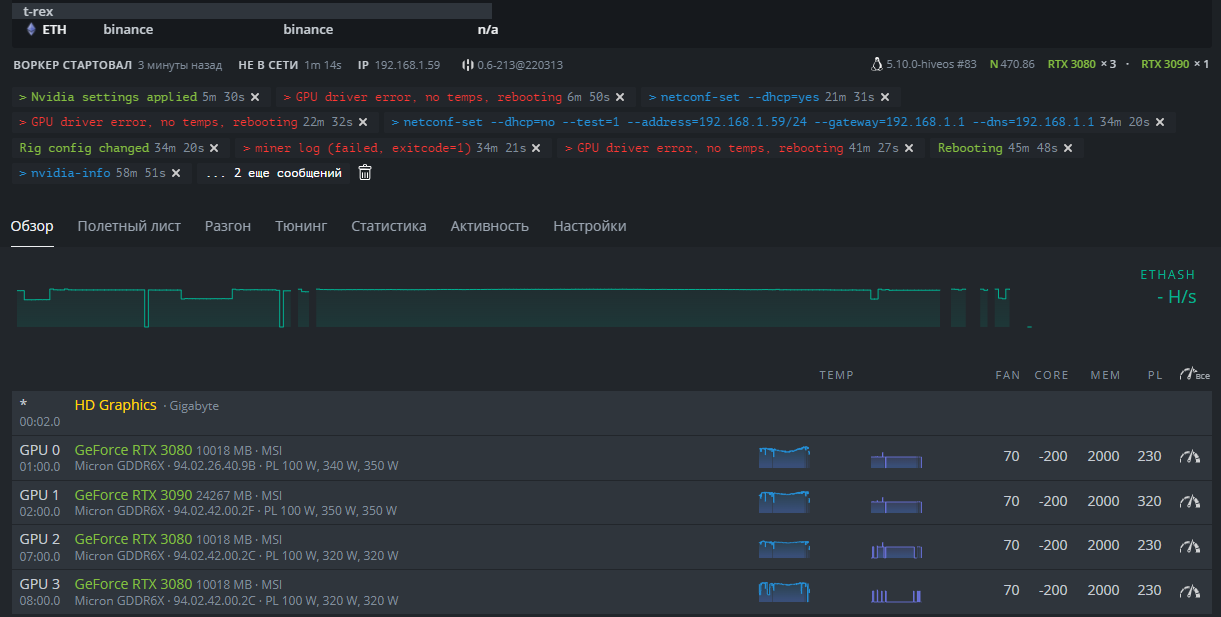
Not having much luck with the memory clock changes. Rig is now rebooting more often. Is there a way to look at the logs to identify at least which card is being reported for this error? It’s not available in the GUI, and I had no luck finding it in /var/log logs available.
Thanks for linking to the article. I’ll reduce memory clock settings even further. If I have to suspect any one card, it would be the MSI 3080Ti. Another of the same card, gave me issues on a separate rig but now runs fine with the settings possibly not working on this rig.
Interestingly, all other instances of similar errors posted in this forum, users are able identify the address from the BUS ID as the error screen clearly shows a “0” temperature for the card in question. I don’t see that in the GUI. Is that because I am running nVidia cards, and in Linux nVidia drivers don’t post tjunction temperatures?
the rig worked fine all night, an error began to appear during the day, video cards were not mined, although they were online
sometimes it just goes offline