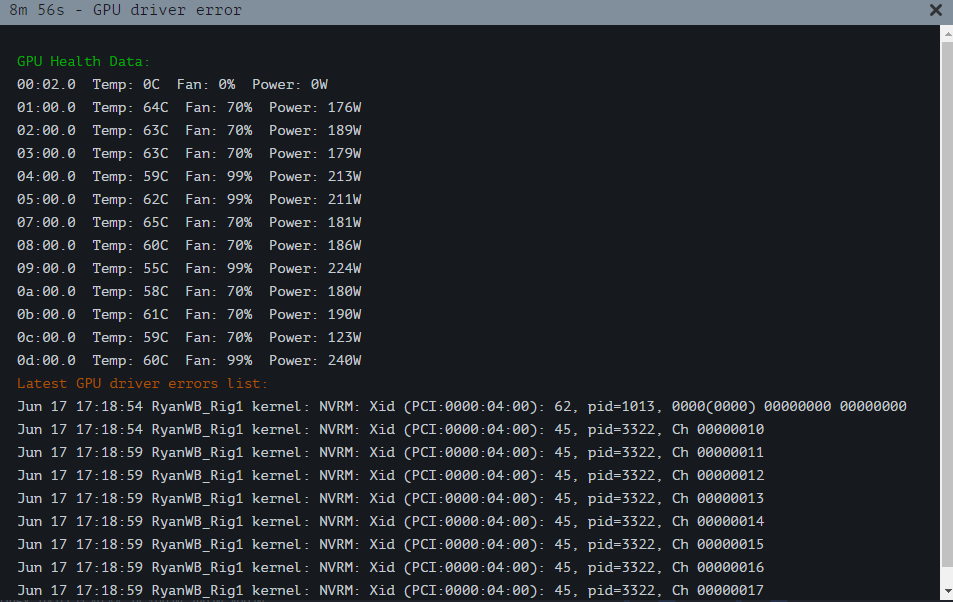
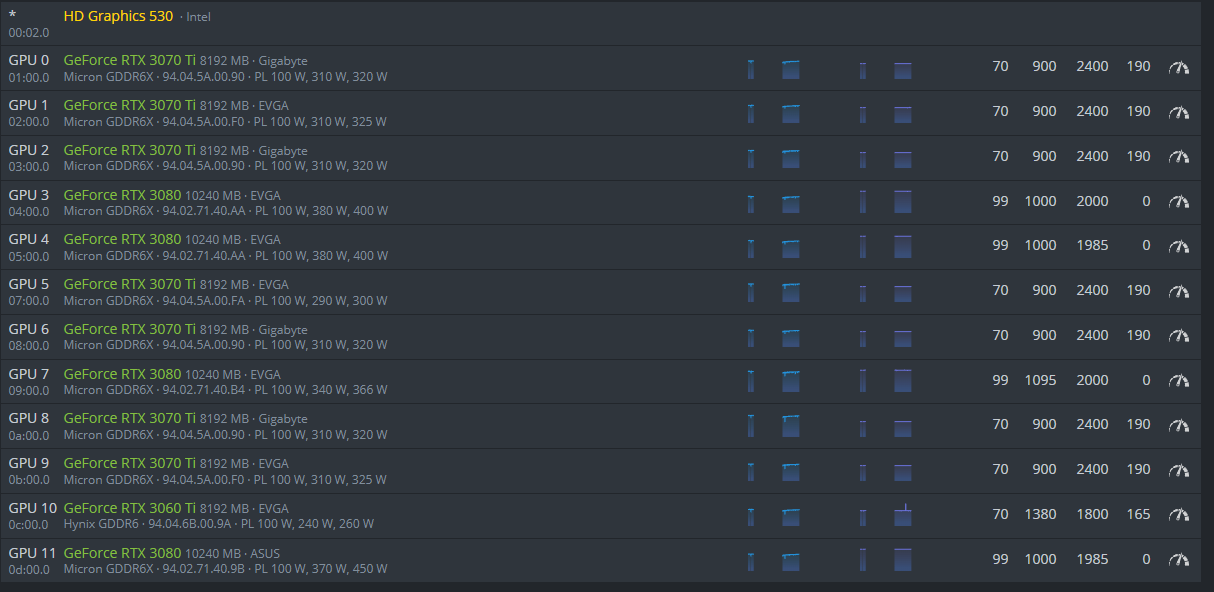
Hey all, I am trying to stablize my rig but its almost daily that it gets a GPU error. I am trying to understand 1. how can I resolve and 2. is there a way I can get my rig to reboot itself and start back up when the error occurs. I’ve played with some settings but it doesnt work.
My rig is as per below:
hiveOS version: .06-616 (linux)
nvidia drivers: N 510.73.05
And I was getting errors with the auto fan so I turned it off and just set my fans on my 3060, 3070 TI to 70%, and my 3080 because they are running hotter to 99%. I never see a temp over 98 degrees usually but I cant see why its shutting down. It always shows the gpu error on the same card. I tried turning down the OC too but not sure what else to do. Any help with #1 or #2 is appreciated.
thanks for the suggestion. So I flashed to latest stable and then updated and keep the same nvidia drivers. And I did lower the mem clock to get a more stable card. It seemed to fix the issue however my rig just went offline but I dont see any errors. Is there away I can investigate why?
My only guess is I turned on the autofan and critical temp of 104 C will stop the miner.I just changed it to reboot but I’m not sure how to tell if this is the reason it went offline. Any suggestions?
Also is there a way to make the rig reboot automatically if it gets a gpu error?
Pcs can crash in different ways, not all will be recoverable via software every time. Set very conservative mem clocks and see if it’s stable, if it is up the clocks on a few select cards and trial and error to find the highest stable mem clocks.
You can use a usb/hardware watchdog or a smart plug to manually reboot if the software one doesn’t catch it