Mining since 2018 (Windows/Nvidia), and I like to think that I’m pretty well versed, but this is my first time using HiveOS/AMD and I’m at my wits end trying to figure this out. Fair warning - I tend to be thorough with my troubleshooting and documentation, in hopes that such information will avoid suggestions of things that have already been attempted.
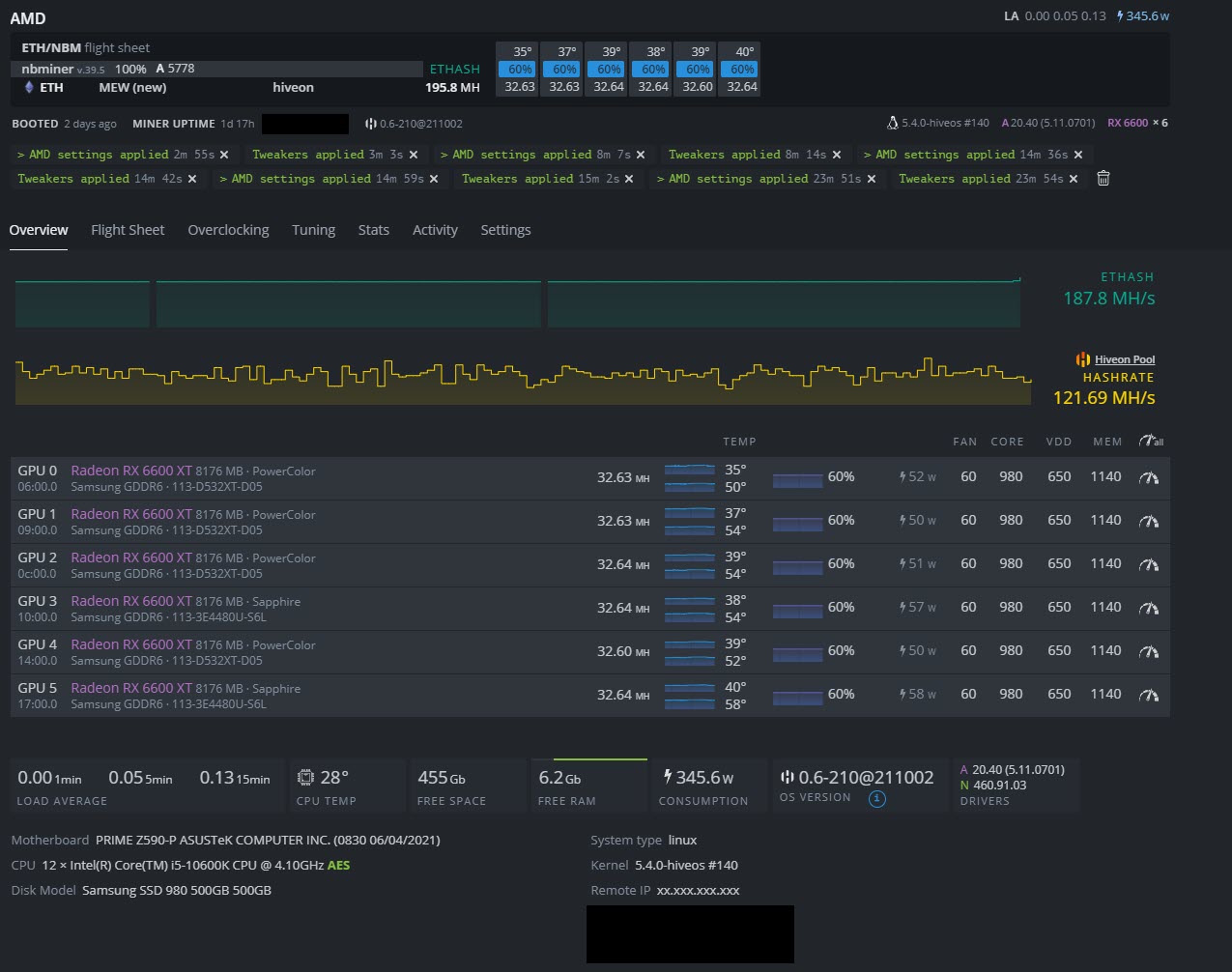
6x6600 XT (4x Powercolor Red Devil/4x Sapphire Pulse - all brand new)
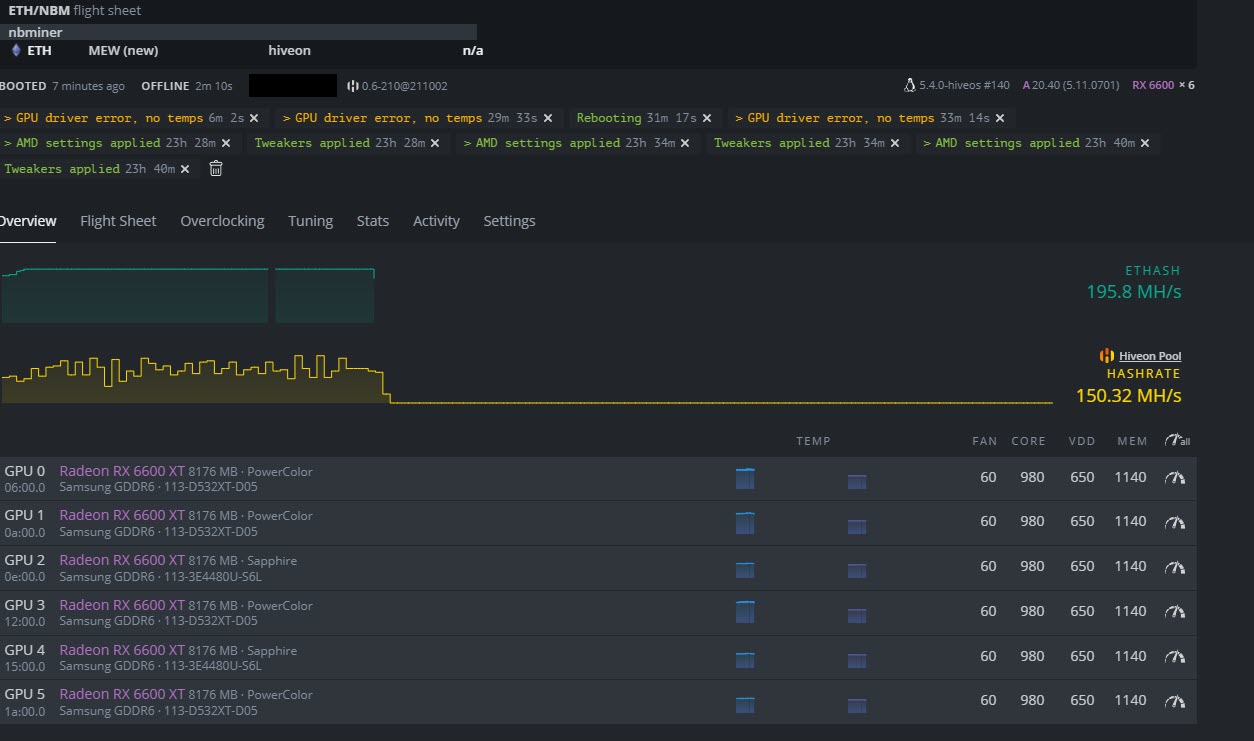
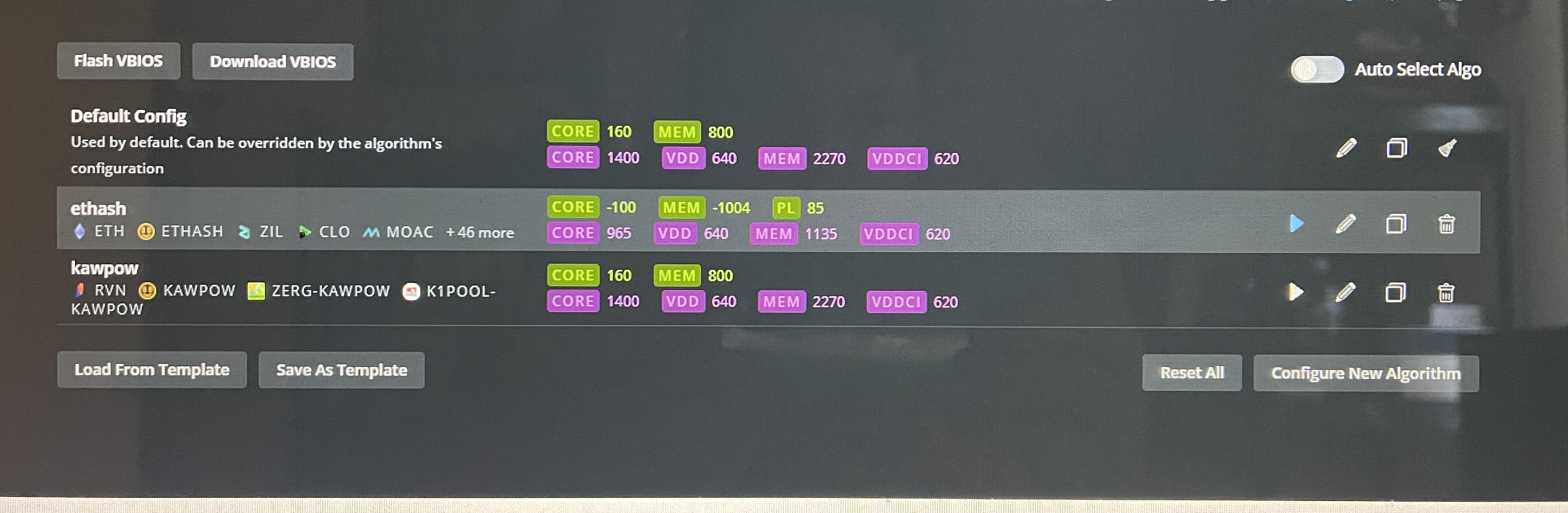
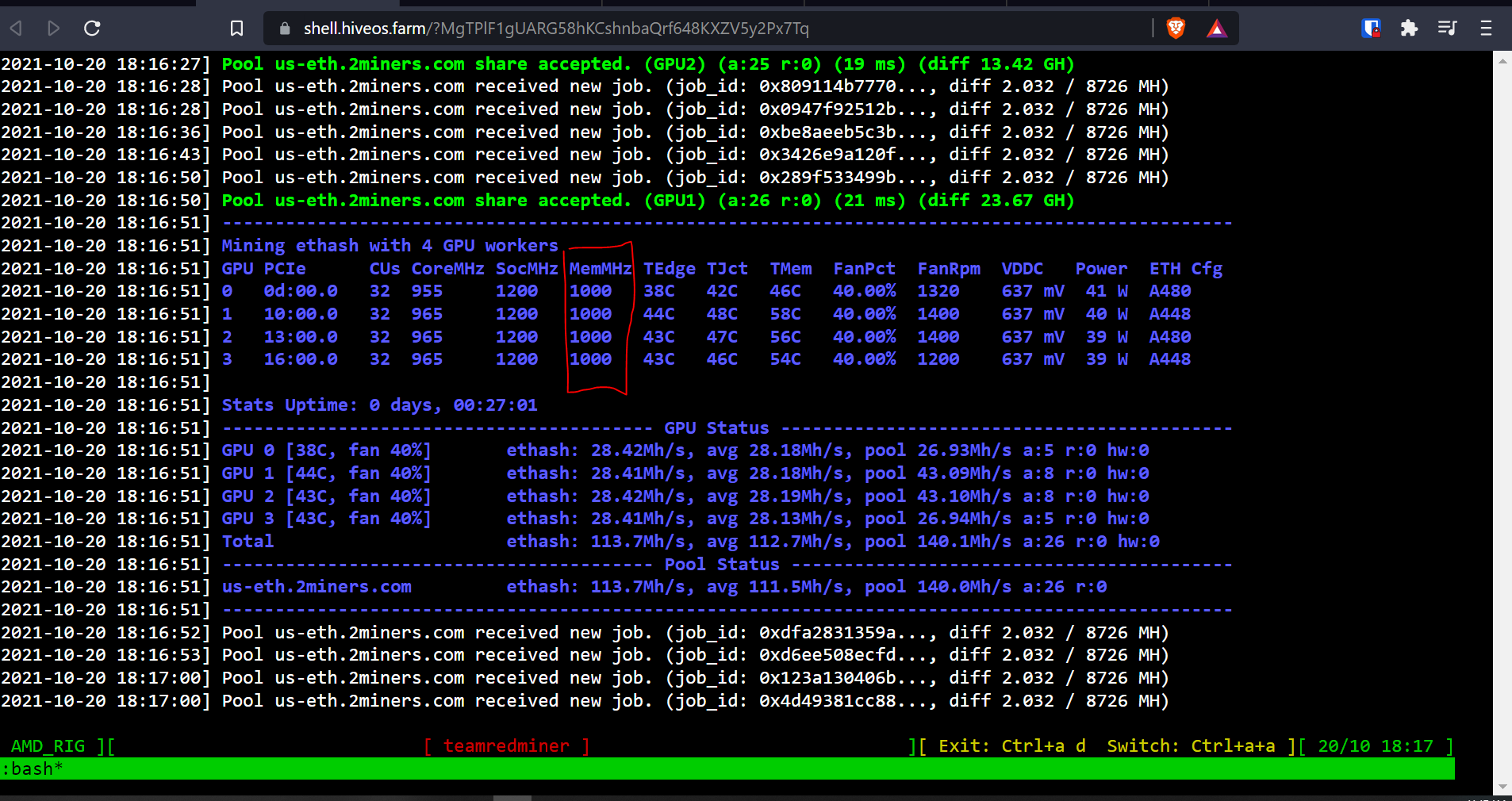
OC = 980 core, 1140 memory, 650 VDD, each card giving 32.64 MH @ 50 watts (avg)
HiveOS version 06-210@201107 with AMD 20.40 (5.11.0701)
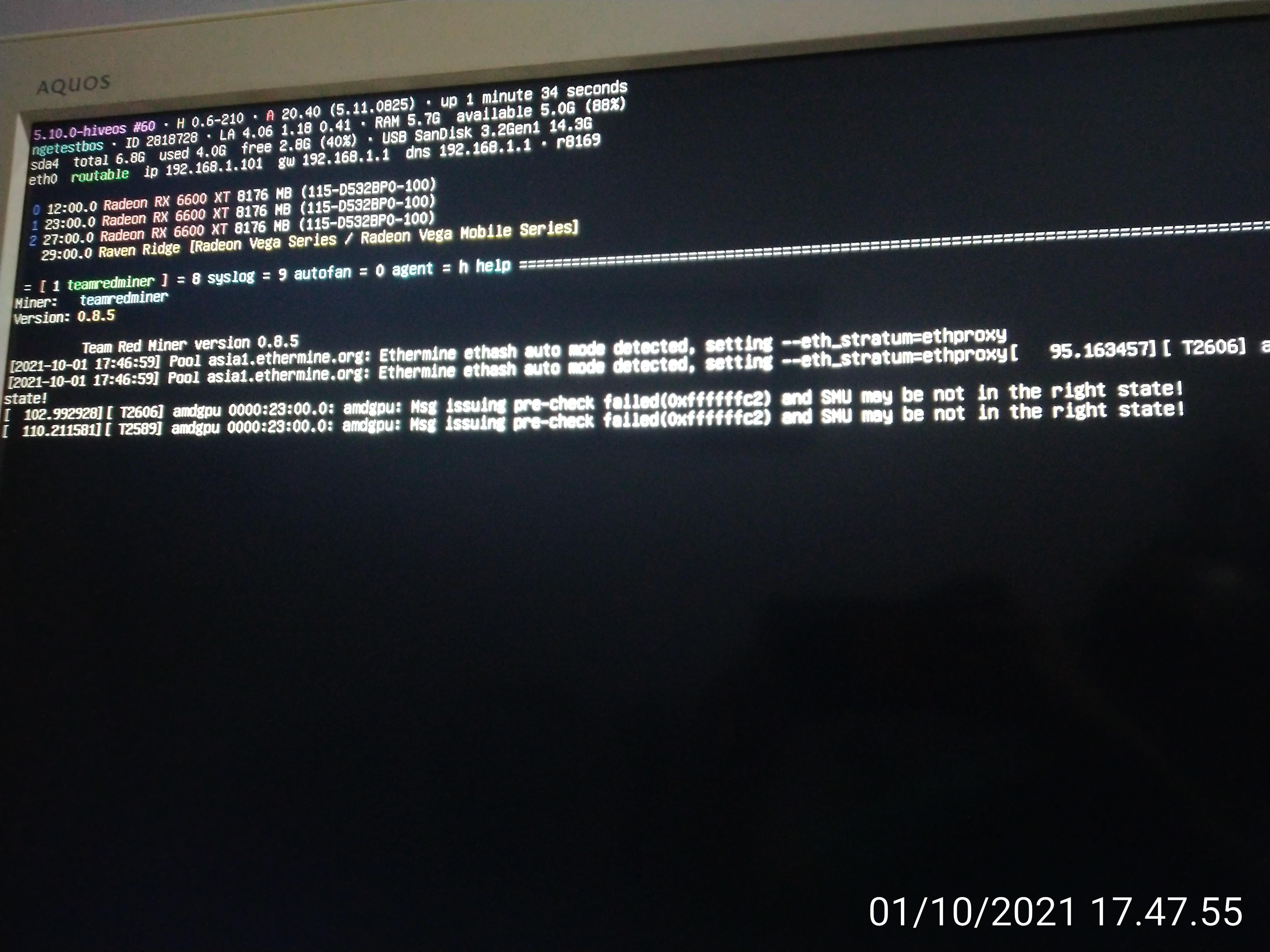
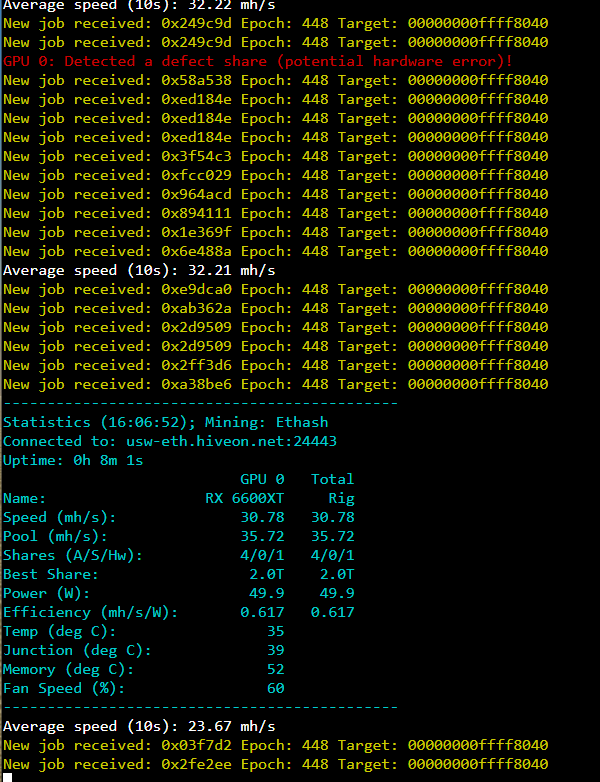
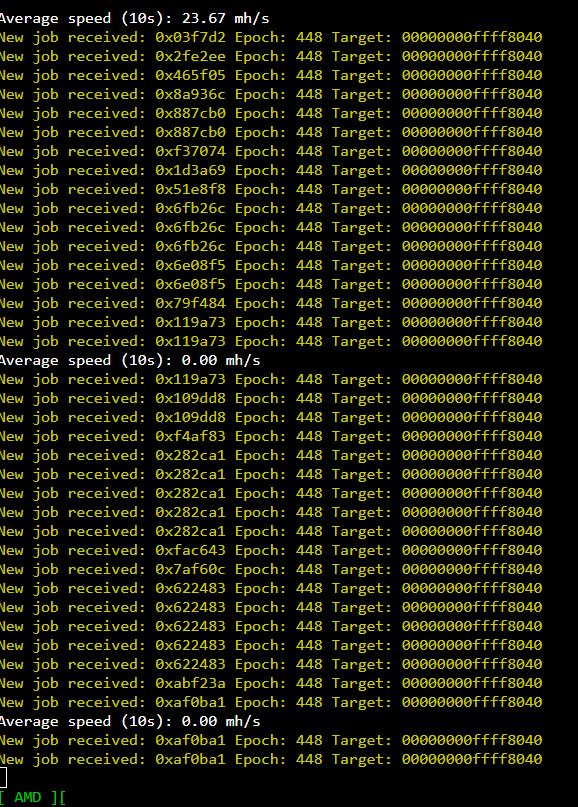
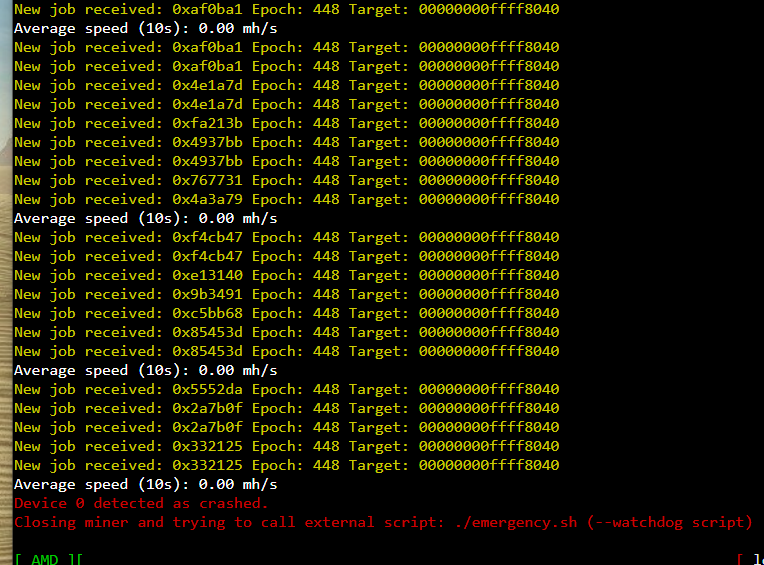
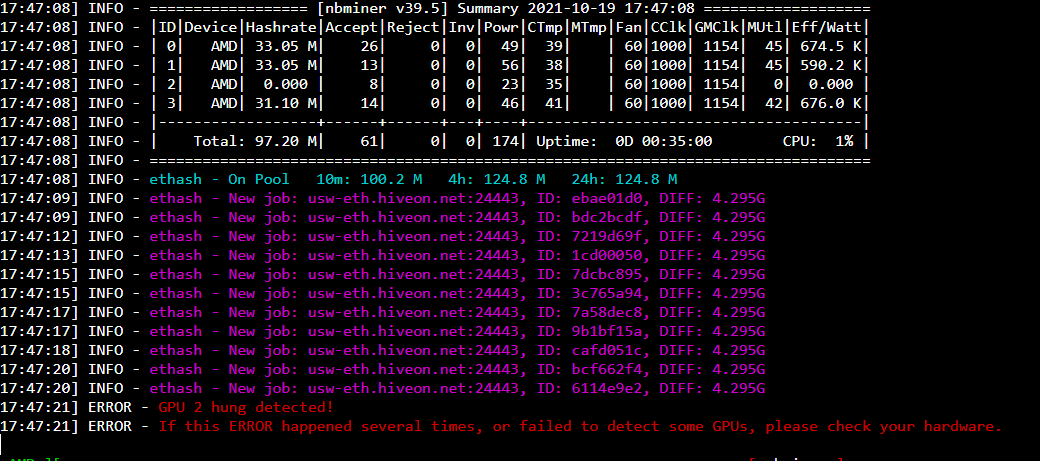
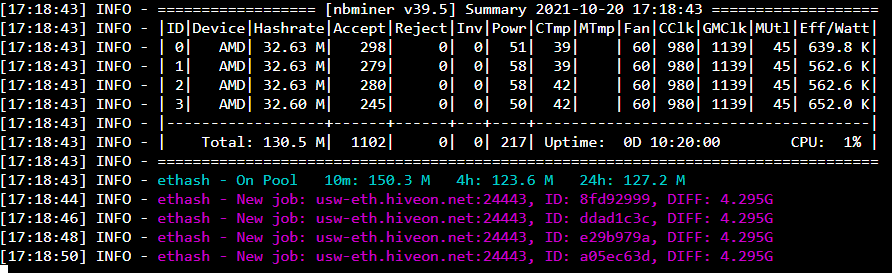
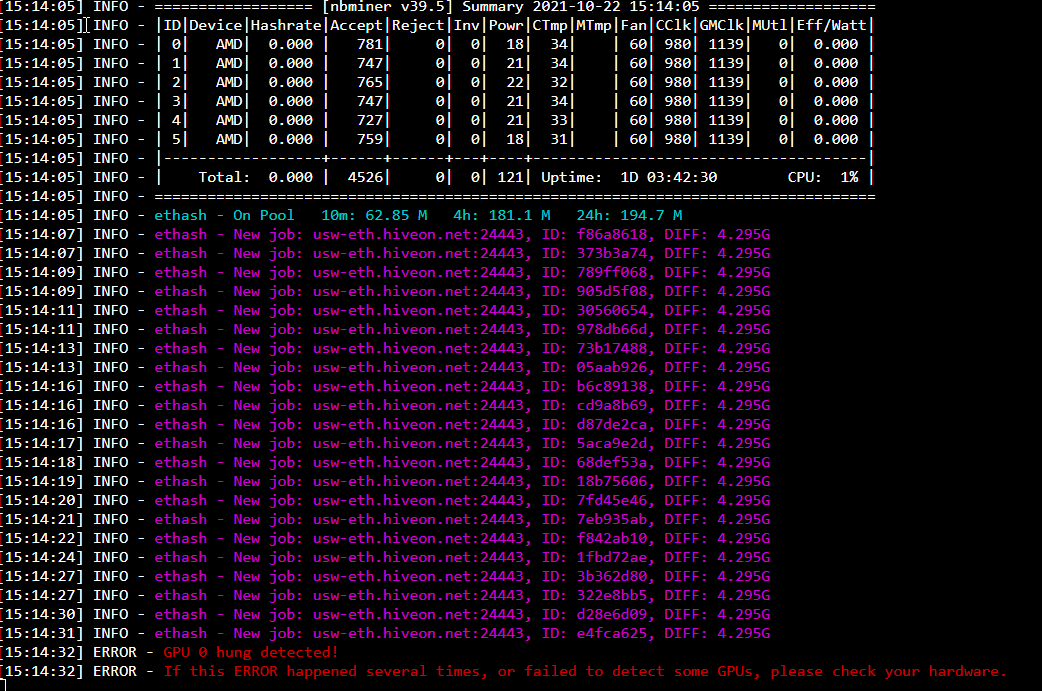
Ran fine for ~ 14 hours. The next day, I noticed that at some point overnight, the rig had crashed, showing “GPU driver error - no temps”.
Most research that I’ve found on this error seems to be with Nvidia cards, but I started troubleshooting 101 and removed all risers from MB (Asus Z590-P with Intel I5-10600K) and began testing cards 1x1 to see which card(s) had failed. Started with PCIE slot #1.
Testing -
GPU 0 (Powercolor) - pcie slot 1 - GPU driver error - no temps
GPU 1 (Powercolor) - pcie slot 1 - working
GPU 2 (Powercolor) - pcie slot 1 - GPU driver error - no temps
GPU 3 (Powercolor) - pcie slot 1 - working
GPU 4 (Sapphire) - pcie slot 1 - working
GPU 5 (Sapphire) - pcie slot 1 - working
Then tried other slots for GPU 0 -
GPU 0 - pcie slot 2 - GPU driver error - no temps
Swapped riser on GPU 0 with known working riser
GPU 0 - pcie slot 1 - GPU driver error - no temps
GPU 0 - pcie slot 3 - GPU driver error - no temps
Verified other GPUs were working in other slots -
GPU 1 - pcie slot 1 - working
GPU 3 - pcie slot 2 - working
GPU 4 - pcie slot 3 - working
GPU 5 - pcie slot 4 - working
Swapped known working power cable and riser (taken from GPU 1)
GPU 0 - pcie slot 1 - GPU driver error - no temps
Rebooted.
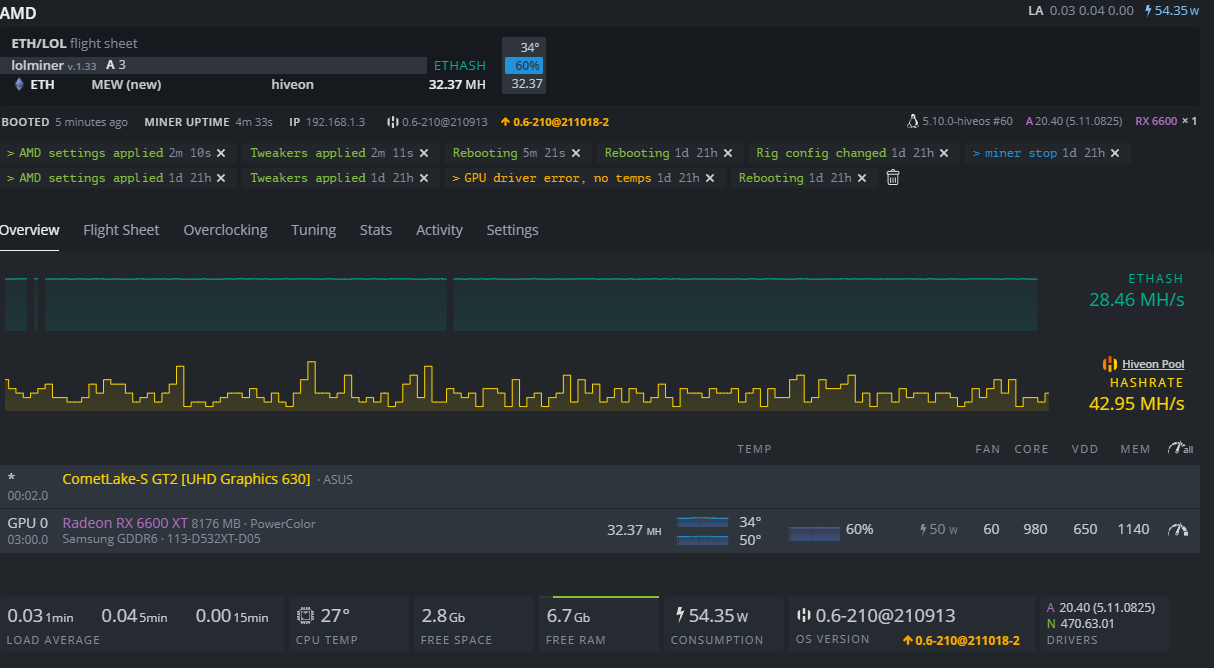
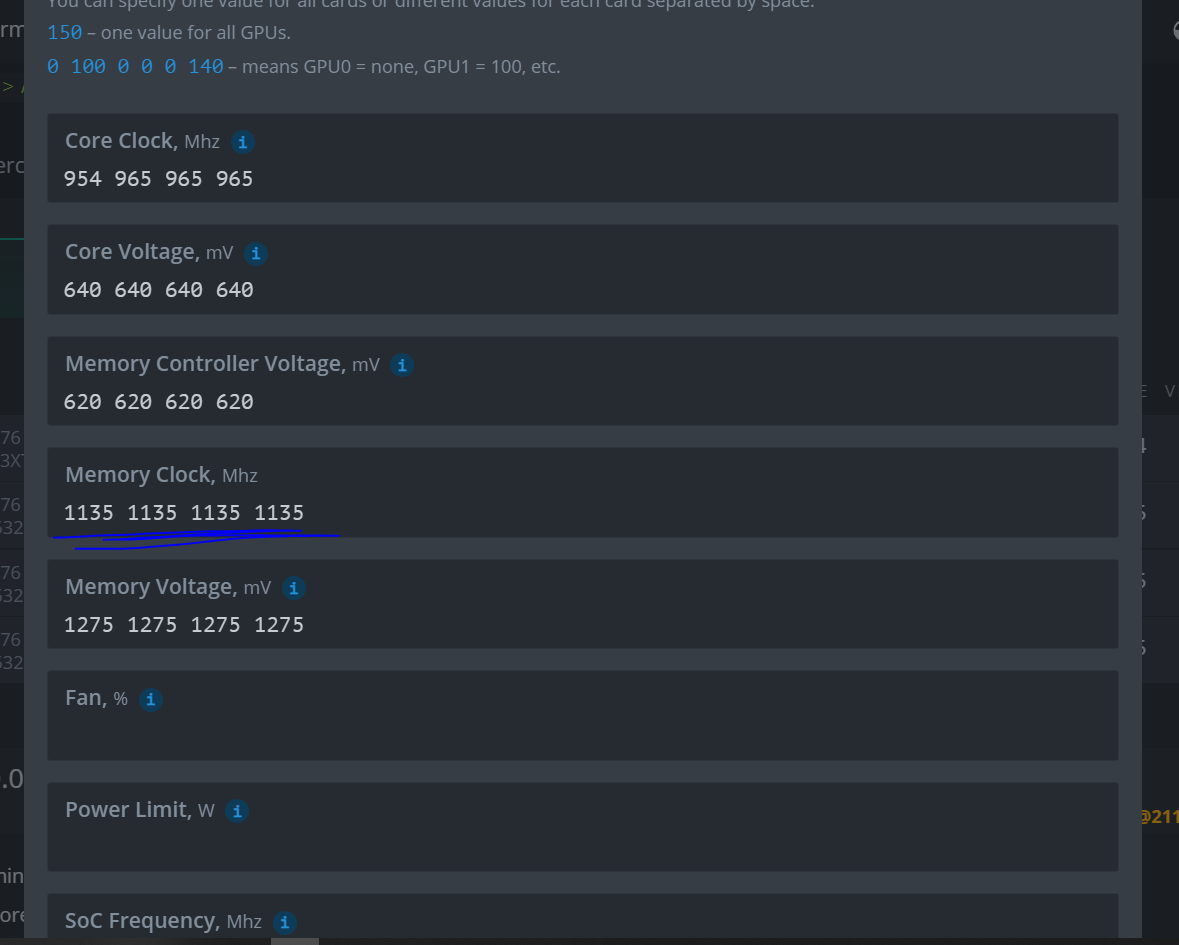
Changed OC settings to 900 core, 1339 memory - working @28.66 MH
Changed OC settings to 900 core, 1339 memory, VDD 700 - rebooted - working @28.66 MH
Changed OC settings to 980 core, 1339 memory, VDD 700 - working @28.66 MH
Changed OC settings back to original 980 core, 1140 memory, VDD 650 = hash dropped to 0. Rebooted.
Changed OC settings back to original 980 core, 1140 memory, VDD 700 = hash still 0. Restarted miner. NBMiner would not start. Rebooted.
Changed OC settings to 900 core, 1139 memory (previously working) - NBMiner would not start. GPU driver error - no temps
Reset all OC to 0. Rebooted.
GPU 0 - pcie slot 1 - working @28.66MH (stock clocks are reporting 1350 core, 1000 memory, using 60 watts)
Changed OC settings to 960 core, 1155 memory, VDD 660, VDDCI 640, MVDD 1300 = hash dropped to 0. Rebooted.
Changed OC settings back to 0 (stock). Deleted flight sheet. Created new flight sheet. Rebooted.
Changed OC settings to 965 core, 1134 memory, VDD 675, VDDCI 637, MVDD 1275 = hash dropped to 0. Rebooted.
Changed OC settings back to 0 (stock) - working @28.66 MH.
At this point, I can’t seem to make any changes to the OC without a failure to start mining and throwing a GPU Driver Error.
I’m confused as to why the OC would work just fine for ~14 hours, then suddenly no longer be able to be applied? I get when OCs are too aggressive and aren’t sustainable. But that shouldn’t affect the ability to apply any OC after that.
And why only on 2 cards? Now, I understand silicone lottery. Hell, I can even concede to one card shXtting the bed, but two?.. Both of which are brand new? 0_o