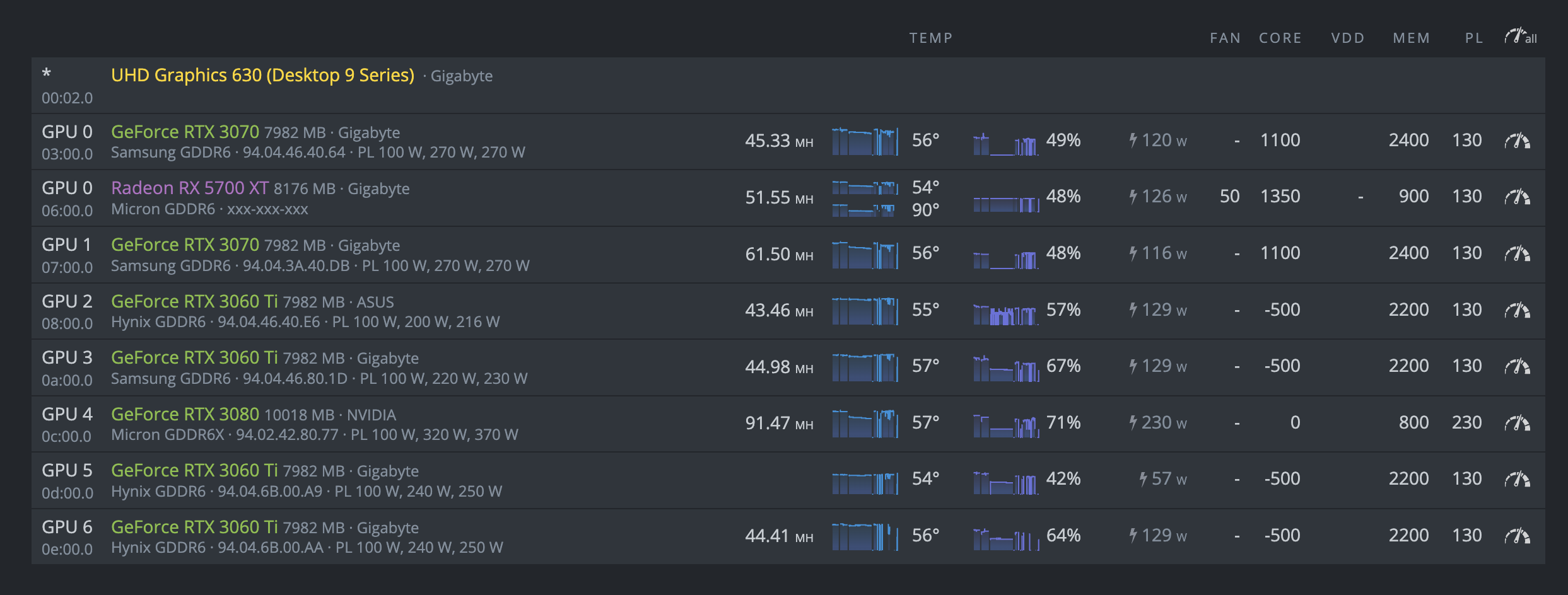
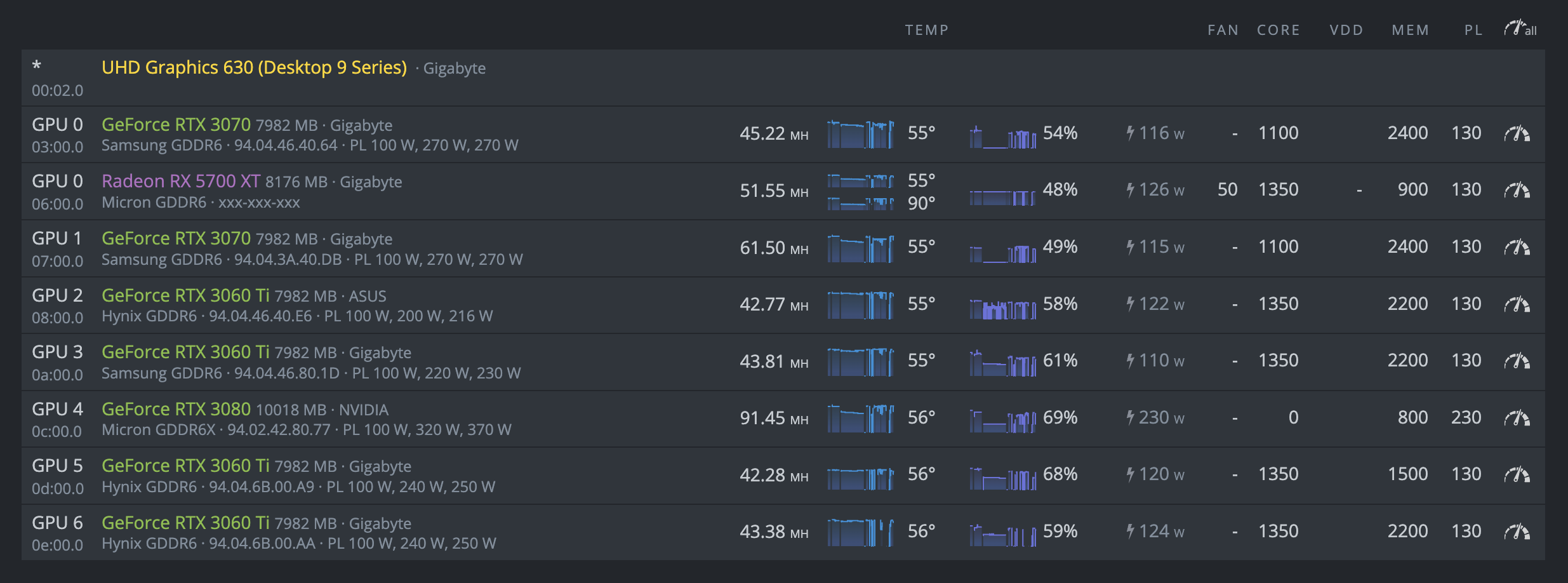
For the past 3 months up until last Friday, everything has been working swimmingly. As of this weekend however, I can’t get the rig to be stable. It will last anywhere from 2 minutes to 4 hours, but always ends up the same.
I’ve been dual mining ETH + ALPH, but currently trying to get it working just on ETH.
Here’s what I’ve tried so far:
Stopped dual mining ALPH
Decreased/removed overclocks
Flashed fresh copy of HiveOS
Removed a couple of GPUs (more on that below)
Updated to latest drivers
Right when this error pops up, the last 2 GPUs in my list stop reporting hashrate. This is even reflected in the console. I attempted disconnecting both of those cards and I was able to mine without issue for 1+ hours.
Next I plugged one in and left the other out, and again was able to achieve stable mining. I thought for sure the card still unplugged was just toasted, but I decided to plug that one back in and remove the other. Stable mining.
At this point I’m not sure what the issue could be. One other thing that I’ve been noticing is that occasionally I will get “DAG verification failed” notice when first starting the mining software. If anyone has any ideas or suggestions, I am all ears. Rig info below:
We’re stable at the moment. I also added a 30 second delay to the overclock settings so the DAG can build without the clock set. Didn’t get the verification failed error this time around.
I’d suggest running each card in windows with your overclocks so you can see the temps.
If the temps are below 100c, you should be fine running them in HiveOS.
Currently, HiveOS doesn’t show the memory temperatures of Nvidia cards.
Also, for your 3080, you can set the core clock to 1080.
The only card I’ve been able to see mem temps on in Windows is the 3080. Dropping the core to 1080 drastically lowers the fan speed, so that worries me that the memory temp is just skyrocketing. Maybe I could just manually set that fan.
You should be using a fixed fan speed anyway, 80% to 100% on all nvidia cards. The fans are linked to the core temperature and not the memory temperature. So basically, leaving them on auto, you are allowing the card to cook itself.
3080 and 3070 should show the memory temps.
3060 Ti you have to look at the hotspot temp.
Should I only remove power limit on that card? I don’t have a lot of headroom with these 1000W PSUs. 3 3060ti’s share a PSU with the 3080, and I have room for maybe 150W on each of them. Also, what’s the lowest memory clock I can go?
for the lhr cards you can use the core clock to control power. but i would remove all. you can go into the negatives, you shouldn’t need to though. if its still crashing below 1400 i would try swapping risers/cables around to rule that out as well. some hynix 3060ti don’t like more than 1500 mem. some will do 3000. samsung will typically do 2600+
also, trex has oc delay built in, so you dont need to put a delay, but thats not hurting anything either
Just wanted to update with my findings. No amount of lowering overclocks worked. Swapped risers and still had the same issue, so I decided to test the card with the DAG issues in another PC for gaming. Absolutely terrible performance and some artifacting was visible. I’m going to assume the card is toast. The rest of the rig is running just fine now.
I had the same issue when I started DUAL Mining ETH + TONCOIN… I had 2 x 3080’s on a 750W PSU, when mining ETH my 3080’s had Poweer Limit of 280W each… which was a total of 560 W for the PSU
(or 560/750= 74%) when started dual mining, each card was using ~300W (80% of PSU usage). Theoretically I had 20% spare or 150W in my PSU, but I inmideately saw the PSU was getting very hot… once, it just stopped working, I had to reset the PSU and it worked again… but the GPUs showed me that “GPU driver error” on HIVEOS every 5mins to 1hr… finally after some hours the PSU just burned, I changed the PSU for a 850W, and the errors dissapeared, it has been more than 1 month since those GPUs are working fine with the new PSU. Your propblem may be that the PSU is not able to mantain the 12V+ when dualmining, making the GPU to stop working and disconnecting from the MoBo. Try lowering the load to the PSU, or changing the PSU for a higher wattage PSU. please let us know how this ends for you…