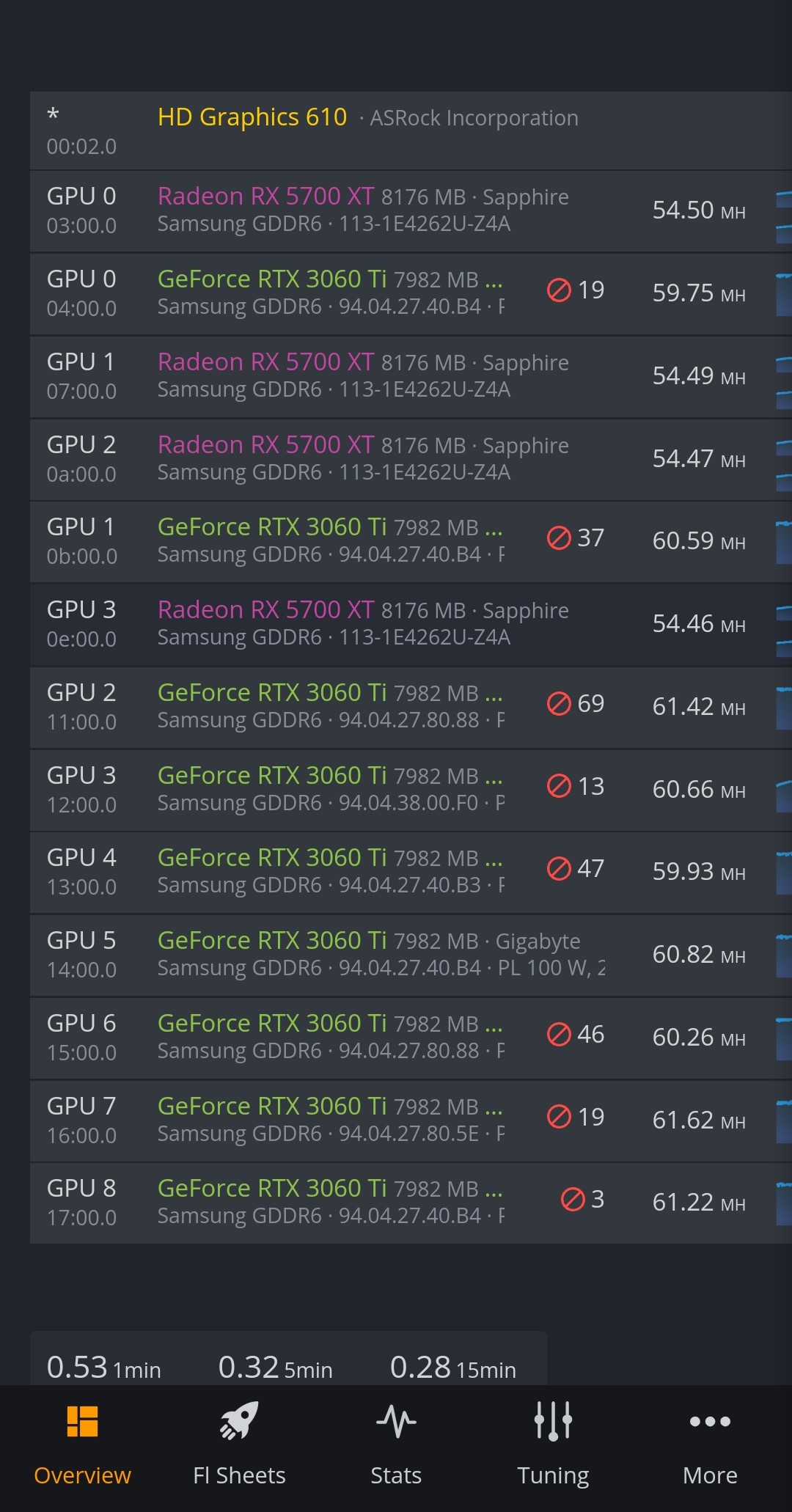
I have found strange behavior for my mixed rigs. It works quite good for at least 1-2 days, but got a lot of invalid shares (nvidia gpus mainly) after then. It took 2 days, 3 days or more often even 4 days without any invalid share and after that fall down to approximately 60% efficiency (valid/invalid shares for the whole mixed rig). After reboot it works as before, no invalid shares for several days and then the scenarios repeats again:
Have similar problem. For me I think its mostly due to rebuilding DAG with the OC settings turned on. I would love to see a WatchDog that restarted the miner after certain invalid shares.
I have the same issue with both AMD and Mixed rigs. They all work perfect for about 3 days, but then start to generate the occasional invalid share on the worker page. Those invalid shares are not listed on my miner statistics page. A reboot fixes the issue for another 3 days.
I have now switched to t-rex miner and executing a script (reboot script) if the dag is rebuilding. The t-rex miner also has much better feature for building dag for RTX-cards so for me the problem is basically solved now.
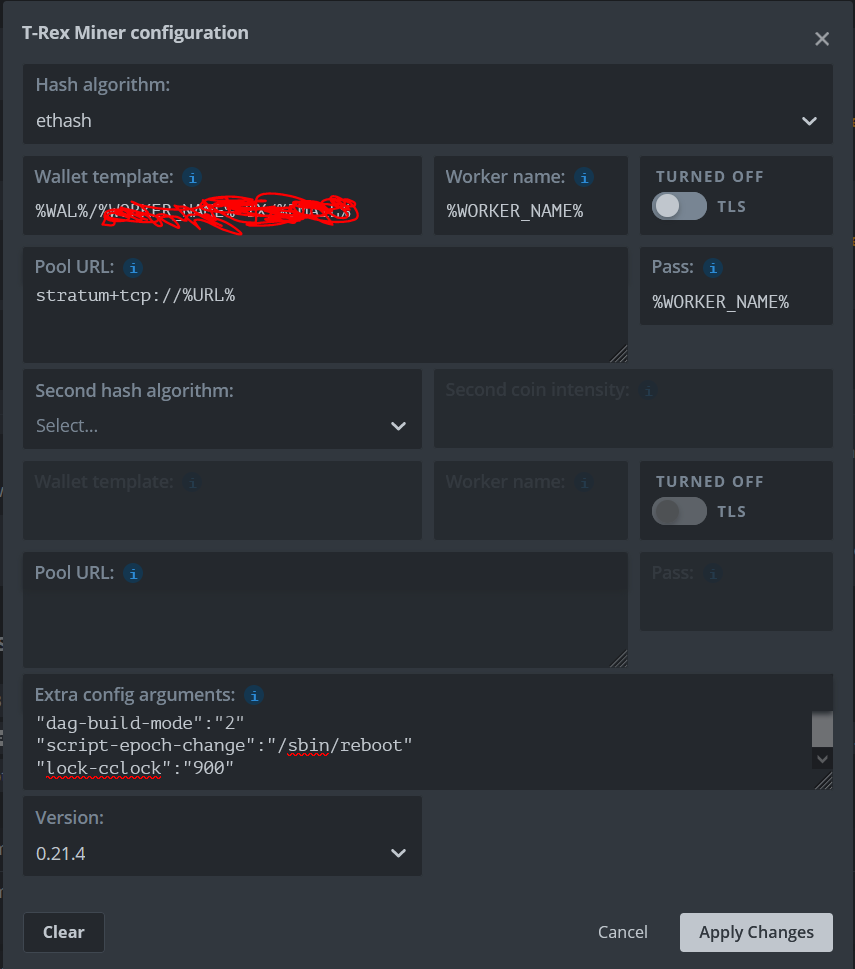
I have set dual miner (phoenix - AMD, T-rex - Nvidia) setup for the purpose and changed T-rex config extra arguments as follows:
“dag-build-mode”:“2”
“script-epoch-change”:"/sbin/reboot"
Everything works now regarding the invalid shares.
Unfortunately the miner hashrate reporting is not working as expected now at the pool:
The reported hashrate is invalid and changes during the period somehow random. I checked phoenix reporting is not working as expected. But i didn’t touch phoenix config at all. Any hint regrading reporting hashrate using dual miner config?
The calculated hasrate is ok.
Thanks.
Im about 99% certain its new epoch.
Gotta create new DAGs, which breaks them if done while clocked.
As we already have the delay on OC settings, we really just need a setting in watchdog that restarts the miner when the epoch steps up.
Frustrating, as it’ll chug along for hours to days with 99.99%+ accepted, then just faults hundreds in a hurry. Threw almost 1000 down the well before i caught it.
Came here looking for at least a workaround.
Normal watchdog doesnt catch it, as its looking for reported hashrate, which doesnt really change when this happens