Great to be a part of this forum and join the mining community.
I have a rig I built recently and have not been able to get more than 3 GPUs mining at the same time.
I’m using HiveOS. I initially tried PhoenixMiner, but it simply did not like my setup as it rebooted constantly. So I switched to a miner which seemed more stable for my system. I’m settled on lolminer as it’s been working and I’ve been mining with 2miners pool. It’s more time than anticipated to get to the transaction level. But it’s progressing.
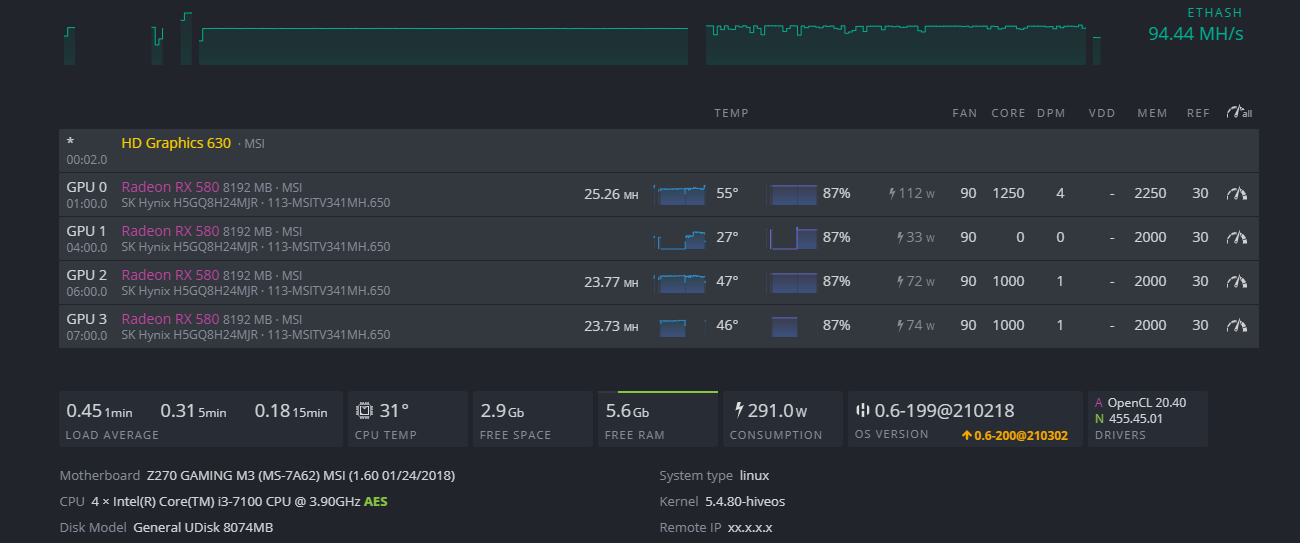
My set is as follows: two PS: 850w servicing Mobo, risers, fans. 900w servicing GPUs. Mobo is Gaming M3 with i3 intel CPU and 8Mb memory. My guess is that I need more power?
Why are you pushing it with 1250 Core clock and 2250 Mem clock? Try starting with modest OC values. Something in the range of last two cards that you have… Then you can gradually start upping the OC as logn as the system is stable.
I got bored with getting that GPU to work and started playing with settings on the one you see to see if I can get the hash rate up.
However, I went back and reset everything to the conservative values you see above. Same problem with the same GPU. I’m going to reduce the Core some more on that GPU to see if that helps, but this same GPU ; though seen by HIVE is not being picked up by the miner process it seems.
Sometimes I get this error, but not all the time, during init.:
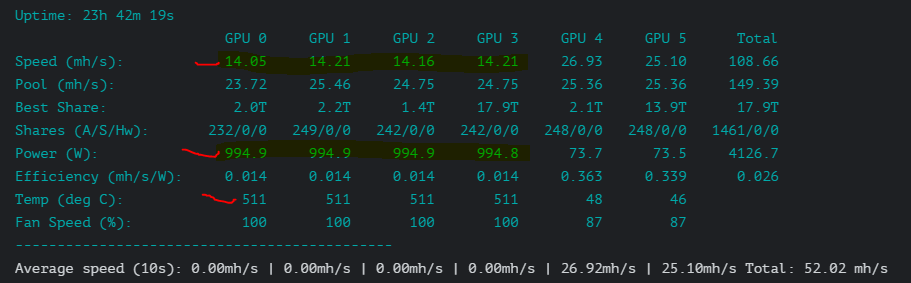
00:02.0 Temp: 0C Fan: 0% Power: 0W
01:00.0 Temp: 35C Fan: 87% Power: 40W
04:00.0 Temp: 511C Fan: 100% Power: 16777215W
06:00.0 Temp: 34C Fan: 87% Power: 35W
07:00.0 Temp: 30C Fan: 87% Power: 36W
I also see this particular GPU go to 100% while the others don’t.
Check your hardware connections and wiring. Risers, cables, …
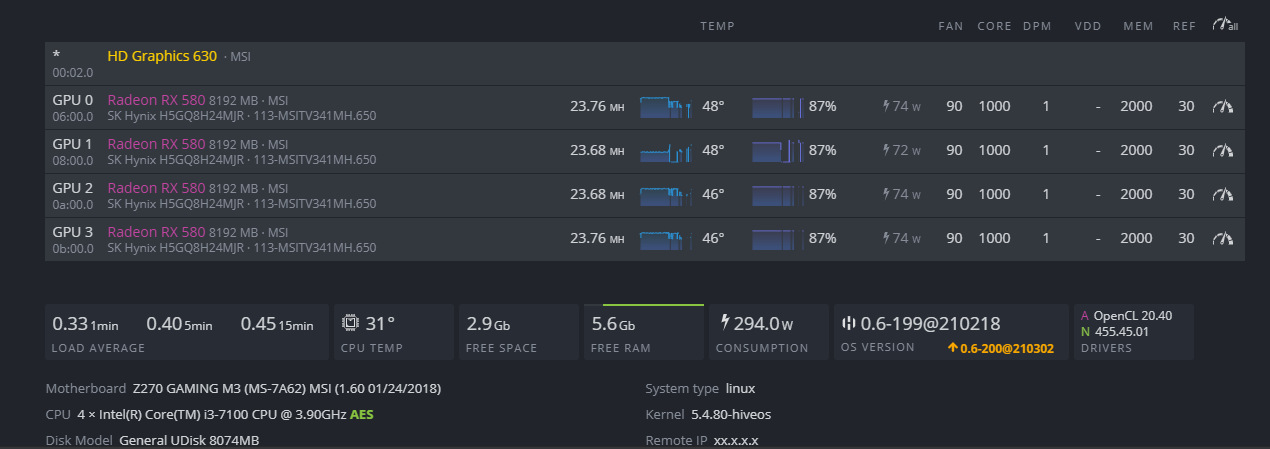
Those cards should go to around 30MHs with core clock at 1145 and mem around 2050. Most probably you have stock BIOS on them. Easiest way to change that is download BIOS from the cards, run Polaris BIOS Editor tool on your PC, load original BIOS into this tool, click on “One click timings”, save BIOS and upload it on your cards. And you will have more stable rig with higher MHs.
Or you can try using “Download VBIOS” from Hive dashboard (Overclocking section).
Hardware and wiring - no conclusive test. Just keep trying. Change GPUs and connect them on different risers. Maybe faulty riser or cable… Check which GPU isn’t hashing, switch places and see if the error stays with GPU or with the riser… If nothing else - try booting with single GPU so to prove that GPUs are OK. Then test risers - one by one…
I did the “Download VBIOS” then ran the Polaris application. Click the bigger box and said yes to all the popups. Save the original file (yes I backed it up just in case). Then used the “FLASH BIOS” option. Does the “Download VBIOS” unlock or does Polaris “unlock” the rom?
I think that is what I will do, in doing the one-by-one replacement and verification. I was hoping for something faster lol.
Thanks to the guidance, I ripped everything down and built back up slowly and it dawned upon me to read up on the motherboard I have and found this in particular which provided some understanding.
y The PCI_E4 slot will be unavailable when an M.2 SSD module has been installed in
the M.2_2 slot.
y The PCI_E2 slot will be unavailable when an expansion card has been installed in
the PCI_E5 slot.
y The PCI_E3 slot will be unavailable when an expansion card has been installed in
the PCI_E6 slot.
y If you install a lar
This showed me that even though I have 6 slots does not necessarily mean that I have 6 slots available simultaneously. So I double-checked my setup to ensure I was not blocking the slots that I was using. During this “re-configuration”, I noticed that the two longer PCI slots (x16) had a light under them when they are active. And the first one was not active. Not sure why the stubs would not work in that slot. Then I noticed that it really has to be secure for that light to indicate that it’s active. Since that slot was finicky I moved things around.
I then ran into some posts that mentioned changing the latency and generation PCI bios configuration. This configuration did seem to impact things. I found that keeping the generation to “auto” worked best for me. Moving it to 1,2 just kept things unstable. The next was the latency. I started from the bottom and moved up until I got the consistent boot with all the GPUs active and seen by Hive and the miner. This setting is currently working at around 128+ cycles with 4 GPUs at the moment. Two of the GPUs are on a 4 USB expansion PCIe expansion card due to the slot limitation.
I would connect the final two GPUs, but my USB cables are too short based on my configuration. So I have to figure that out or get longer USB cables. From what understand they should be USB 3.0 and not beyond a certain length?
Until then, I will let things run for a day two before mucking around with the overclocking and/or flashing the bios I have on them. Any comments/suggestions will be appreciated.
My guess was the two GPUs on the expansion card. I can never tell which GPUs the logs a referring to. The journey continues…
I’m leaning towards that I need a different motherboard to support what I am doing.
I have to also say that I have better stability with lolminer versus any other I have tried.
Phoenix miner throws may errors and doesn’t handle my setup at all.
ETHMiner doesn’t connect to the mining pool at that I working with.
Thank you @farkeytron. I took your cue and started looking at my whole riser setup. I didn’t see anything obvious but did take the notion of finding out which GPU was failing. The system seems stable with 3 GPUs. So it seemed constantly the same GPU that was “crashing” and causing the system to reboot. So I went one-by-one to narrow which one it is. (be nice if hive or the miners would tell you that?). Once I found which one, I took everything out for that GPU and double-checked and cleaned everything. Replaced the riser set up with a newer one. Put everything back and it failed again.
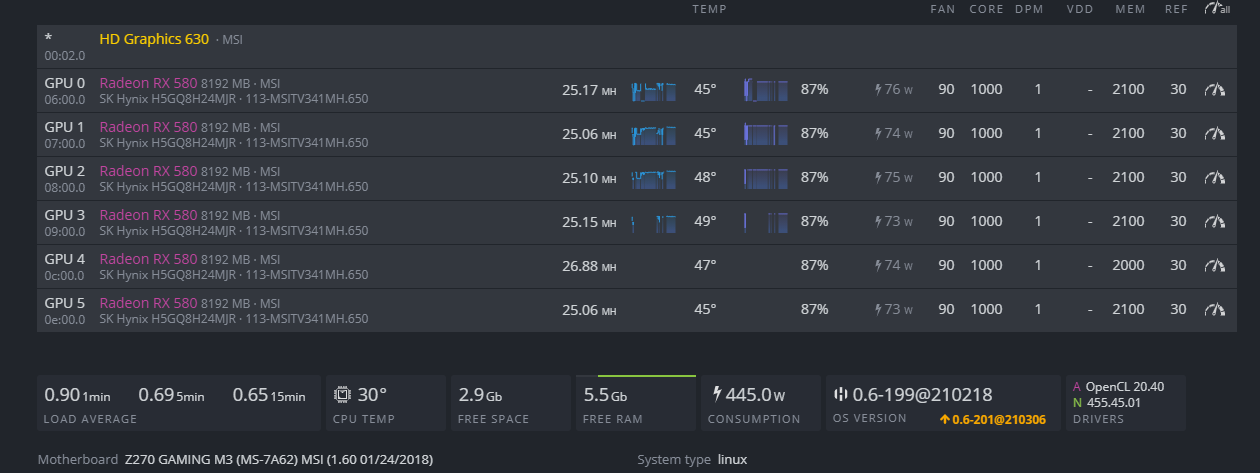
Next, it occurred to me that it has to do with the slots and the Mobo. I have Ubic? 4 USB adapter and decided to put that in place in the PCIe 1x slot and avoid using the 16x slots. I put 3 cards on the adapter and left the other card in the other PCIe 1x slot. It has been running stable for 12 hours, with no reboots and hashing at total of 90+ mh/s.
My next step is to put all 4 on the adapter and put on a 5th.
I found on Reddit that it seems that others have the same issue with this Mobo. To where they can, at best, get 4 GPUs. Grant it this was back in 2017 when the board was new. Yet it makes sense. I think I will start looking for a “newer” Mobo/CPU combo. Though I hear ETH is changing, sounds like I will be mining something else in July lol. In meantime…ETH it is.
I can’t help but see that there should be some diagnosis tools on Hiveos, but it is particularly interesting that Hiveos detects the GPUs but the miner software (Lolminer being the most stable) all have a different opinion per se.
Updated to 6 GPUs and has been running stable with my latest configuration. The only time it went down is when I pushed GPU4 memory. Put it back and it’s been stable with no issues so far (knocking on wood). It’s only been 2 hours…I will let this run for the rest of the day.
If this stays stable, I will add more GPU (i.e. Rx 580s). I have space for 2 more in slots.
In the meantime, does the choice of mining pool impact how fast I will make ETH? Currently using 2miners and I like the web interface to see what my miner is doing at the moment. But I see there are others that seem to rank higher.
Thank you again for your help in this and hopefully, my journey thus far helps someone else.
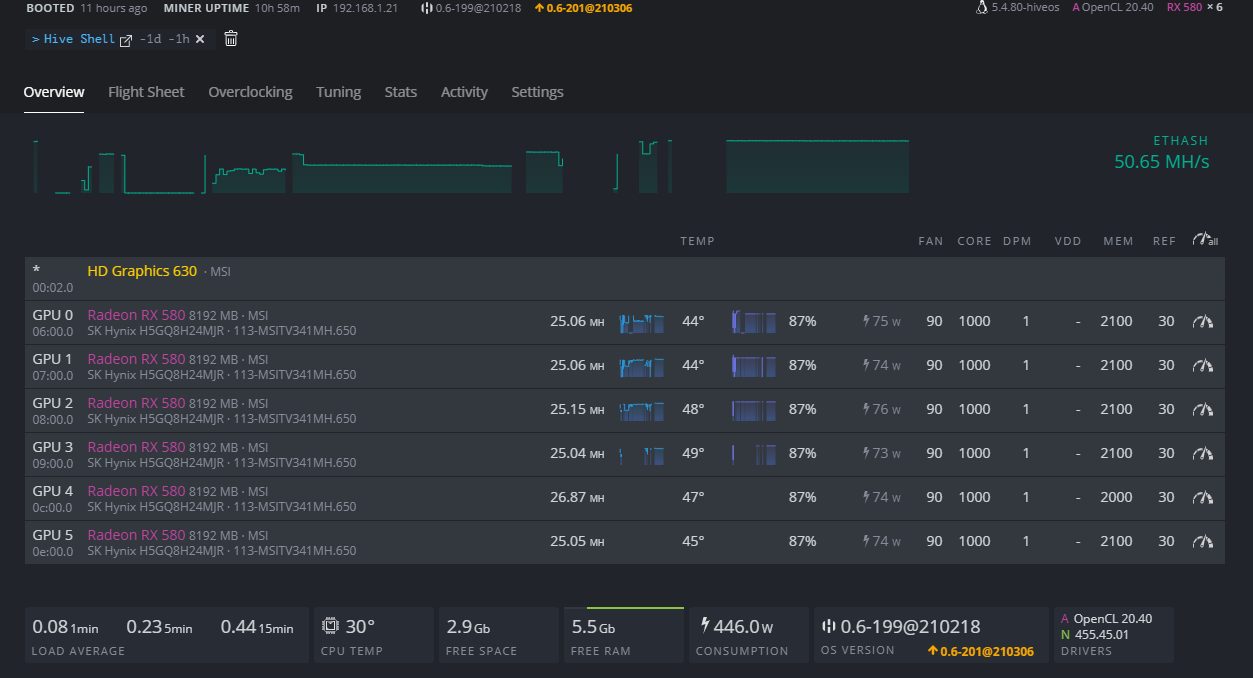
The rig has been up for 10 hours straight and stable! I am so happy that it’s at this point but also
afraid to change anything (i.e. OC, flashing, etc). The only thing I will change is add two more GPUs.
Last night, I saw it reboot a couple of times and checked the connections, and saw that one of the expansion cards had moved. I need to secure them but they are running stable.
Let me know what you think should be the next move? OC, flash? New rig? leave it? I will definitely add the two more cards.
I will take on @farkeytron advice on potentially moving to Hiveon once I see my first payout. However, how does that work in moving from one farm to another? My guess is that you just lose whatever you minded on that farm if you don’t reach that “pay-out” amount?
Rebooted and back to normal, and the 4 involved are clearly the ones on my Ubix 4 USB expansion card…any way to go about understanding what happened? Any thoughts?