


I am not sure that this is because of the Nvidia cards but that is what I have ATM. So here we go:
For the past 1 or 2 months, I started to get an increasing amount of errors. First, I thought it is the OC, so I tried tuning down GPUs that were throwing the errors. Then I have tried turning off services such as Auto fan and GPU dog.
First, only rigs #2 and #3 had these errors, now rig #1 also started having synchronous errors.
All rigs are connected to the same internet connection/router.
All rigs take electricity from different plugs but from the same room.
I just can’t isolate the problem no matter what… HELP!
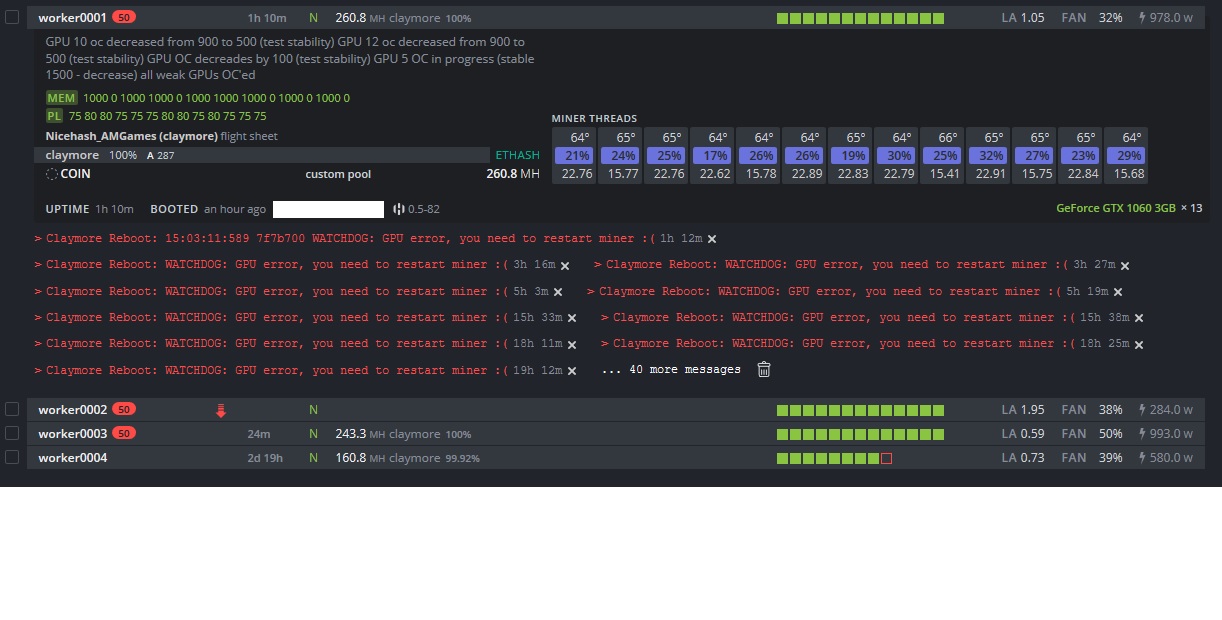
QUOTE from one of the errors:
=== Last 50 lines of /var/log/miner/claymore/lastrun_reboot.log === 21:02:22:089 711f5700 Create GPU buffer for GPU5 21:02:22:091 759fe700 Setting DAG epoch #231 for GPU0 21:02:22:091 759fe700 Create GPU buffer for GPU0 21:02:22:609 759fe700 CUDA error - cannot allocate big buffer for DAG. Check readme.txt for possible solutions. 21:02:24:554 691e5700 buf: {“params”:[“000000bd1360c195”,“04a3fa11bc92b0688ffd46fcd172741eed4f3ec77309711b3c0f92600ce8a125”,“7c68debb7a16f97d6a9878390e4287e266c558315b590d91d02772859f3b2651”,true],“id”:null,“method”:“mining.notify”} 21:02:24:554 691e5700 ETH: 11/18/18-21:02:24 - New job from daggerhashimoto.eu.nicehash.com:3353 21:02:24:554 691e5700 target: 0x000000007fff8000 (diff: 8590MH), epoch 231(2.80GB) 21:02:24:554 691e5700 ETH - Total Speed: 0.000 Mh/s, Total Shares: 160, Rejected: 0, Time: 00:45 21:02:24:554 691e5700 ETH: GPU0 0.000 Mh/s, GPU1 0.000 Mh/s, GPU2 0.000 Mh/s, GPU3 0.000 Mh/s, GPU4 0.000 Mh/s, GPU5 0.000 Mh/s, GPU6 0.000 Mh/s, GPU7 0.000 Mh/s, GPU8 0.000 Mh/s, GPU9 0.000 Mh/s, GPU10 0.000 Mh/s, GPU11 0.000 Mh/s, GPU12 0.000 Mh/s 21:02:24:929 66dbf700 srv_thr cnt: 1, IP: 127.0.0.1 21:02:24:929 66dbf700 recv: 51 21:02:24:929 66dbf700 srv pck: 50 21:02:25:066 66dbf700 srv bs: 0 21:02:25:066 66dbf700 sent: 511 21:02:25:610 759fe700 Set global fail flag, failed GPU0 21:02:25:610 759fe700 GPU 0 failed 21:02:25:610 761ff700 Setting DAG epoch #231 for GPU0 21:02:25:610 761ff700 GPU 0, CUDA error 11 - cannot write buffer for DAG 21:02:28:610 761ff700 Set global fail flag, failed GPU0 21:02:28:610 761ff700 GPU 0 failed 21:02:32:618 2c0bc700 em hbt: 2, fm hbt: 43, 21:02:32:618 2c0bc700 watchdog - thread 0 (gpu0), hb time 7009 21:02:32:618 2c0bc700 watchdog - thread 1 (gpu0), hb time 7009 21:02:32:618 2c0bc700 watchdog - thread 2 (gpu1), hb time 7009 21:02:32:618 2c0bc700 watchdog - thread 3 (gpu1), hb time 7009 21:02:32:618 2c0bc700 watchdog - thread 4 (gpu2), hb time 7009 21:02:32:618 2c0bc700 watchdog - thread 5 (gpu2), hb time 7009 21:02:32:618 2c0bc700 watchdog - thread 6 (gpu3), hb time 7009 21:02:32:618 2c0bc700 watchdog - thread 7 (gpu3), hb time 7009 21:02:32:618 2c0bc700 watchdog - thread 8 (gpu4), hb time 7009 21:02:32:618 2c0bc700 watchdog - thread 9 (gpu4), hb time 7009 21:02:32:618 2c0bc700 watchdog - thread 10 (gpu5), hb time 7009 21:02:32:618 2c0bc700 watchdog - thread 11 (gpu5), hb time 7009 21:02:32:618 2c0bc700 watchdog - thread 12 (gpu6), hb time 7009 21:02:32:618 2c0bc700 watchdog - thread 13 (gpu6), hb time 7009 21:02:32:618 2c0bc700 watchdog - thread 14 (gpu7), hb time 7009 21:02:32:618 2c0bc700 watchdog - thread 15 (gpu7), hb time 7009 21:02:32:618 2c0bc700 watchdog - thread 16 (gpu8), hb time 7009 21:02:32:618 2c0bc700 watchdog - thread 17 (gpu8), hb time 7009 21:02:32:618 2c0bc700 watchdog - thread 18 (gpu9), hb time 7009 21:02:32:618 2c0bc700 watchdog - thread 19 (gpu9), hb time 7009 21:02:32:618 2c0bc700 watchdog - thread 20 (gpu10), hb time 7009 21:02:32:618 2c0bc700 watchdog - thread 21 (gpu10), hb time 7009 21:02:32:618 2c0bc700 watchdog - thread 22 (gpu11), hb time 7009 21:02:32:618 2c0bc700 watchdog - thread 23 (gpu11), hb time 7009 21:02:32:618 2c0bc700 watchdog - thread 24 (gpu12), hb time 7009 21:02:32:618 2c0bc700 watchdog - thread 25 (gpu12), hb time 7009 21:02:32:618 2c0bc700 WATCHDOG: GPU error, you need to restart miner
21:02:32:618 2c0bc700 Rebooting