After 2 days of struggling with BIOS settings I ended up with ONLY;
Enabling 4G Decoding
All PCI-E slots to Gen-1
But after 2 days of stable (but not as much hashrate as before for 3 gpus) mining; one of GPUs reported as DEAD, and normally system rebooted.
After reboot it came up with gpu driver error with another GPU, and again normally system reboot command operates but system didn’t power on again.
I know theese problems may occur because of bad risers, bad OC etc. I had also faced theese errors back on my old mobo but everytime it did the reboot itself and let me tweak with oc settings. For one time I waited patiently for about 10 repeated reboots. Just to see if it works as it should or not.
But this new mining mobo unfortunately not. But interestingly it reboots good on first error, but not after second error.
In the HiveOS.farm web interface, clear the overclocks, put the rig in maintenance mode with drivers. Some GPUs will allow increasing overclocking tweaks after booting but will not boot properly with them that high.
With the Pro 2, make sure you are NOT plugging the (2) 6-pin ports on the motherboard into your your power supply. The board does not require power from any sources other than the ATX and CPU ports.
Mine is running PCI Gen2, and I have yet to disable the onboard GPU. We’ll see when I try to add the last (2) GPUs this weekend:
Thanks for suggestions, I need kind of automated mining, so maintenance mode first, then doing OCs idea is not so good way for my needs. But information is gold anyway, thanks.
On my initial setup for this mobo no matter what I tried, it didn’t show up with 7 gpus, just 6. After I plugged in thoose (2) 6-pin aux, it showed up. But now I tried your way and shocked to see normally booting with all 7 gpus, very very interesting. I can’t help ask myself so what made 7th gpu showed up back then and why the heck they put that aux supply 6-pins to mobo
About pci-gen option; actually I tried all of them except gen3. Gen-1,Gen-2 and Auto. But didn’t notice any difference, at the end just because not to utilize unneccesary pci-e bandwidth I prefer gen-1.
Apart from all theese good information and suggestions, sorry to say that but I couldn’t sense any relation with not powering-on the system on 2nd error. Shouldn’t it related with bios power settings or something like that?
I’d eliminate an potential power issues first, especially if you have high power consumption GPUs.
Are you seeing any unusual load averages? Note mine with (10) GPUs is below .99 by quite a bit.
If you have nVidia based GPUs, did you run this from a shell to confirm there are not high PCI errors: nvidia-smi dmon -s et -d 10 -o DT
It is only my theory, but I am guessing the 6 pin outputs are to provide 75W of power to fans with a breakout cable or bus. The board itself definitely does not have the connectors for 12GPUs of fans.
Odds of hitting a GPU which is generating comms issues increases as count increases. I have a few in my collection which I no longer include in my large rigs because of the intermittent and flaky symptoms you describe.
1 GPU prevents completing post above 950 mem freq
2 GPUs prevent driver loads on most risers
2 flake out between 12-48 hours and lock up the rig
At one time, they were all rock solid performers
You may find a flaky GPU in your mix creating the issues.
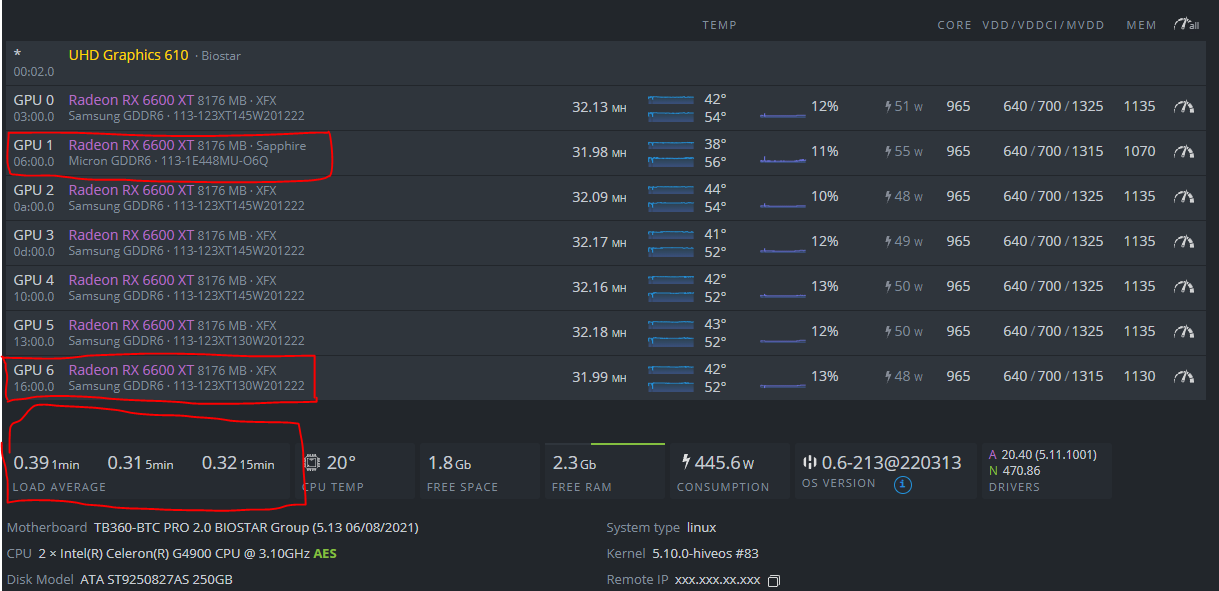
I’ve 7 units of 6600 XT’s, which are known as one of the most efficient gpus. Energy efficiency and investment step ease ( being relatively cheaper ) was my priorities when I decided to step-in mining business.
I’ve 1000 watt Gold level FSP Hydro PSU and load averages are just fine, I’ve also tracking power consumption with meter and I can verify there is not so much variations ( 440-450 watt ). BTW I’m an electrical engineer and we also don’t like power fluctuations so much
Last issue showed me that initial error was related with GPU 1, which is sapphire nitro+ with micron memory. And after GPU DEAD error related with this GPU, after reboot 2nd error (gpu driver error) was related with GPU 6, XFX Swift which is my first purchase back in november 2021. I’m guessing about bad riser but then asking myself “why there was no error in my old MSI Gaming Z system”. Makes no sense but it wouldn’t hurt chaging the riser I believe.
With my old mobo I could stick on relatively more aggresive OC settings because if there was an error it always succesfully rebooted ( sometimes several times ) and started mining, but now I need to stay more secure side for theese 2 gpus. So I expect less errors. Hopefully none, except power shortages.
I’ll keep monitoring the rig for further errors and reboot behaviour.
Increase your voltages for a week, you might have one or more that are poor samples. GPU dead errors can be for number of reasons, but are essentially risers and or overclocks(impacted by power). Once things go wrong on the GPU and or PCI bus, all sorts of errors are reported.
I’ve made some tweaks on problematic GPUs OC settings and this helped with stability issues, but last night I faced the same issue notated on this topic.
Firstly I want to mention that “Power Cycle” setting is enabled on hiveos settings, I’d prefer power off and on instead of reboot.
Rig rebooted after initial “gpu driver error”, after power off and on rig booted and came up with same “gpu driver error”, this is the critical part.
After second power off, even if it should power on again, it simply won’t.
This issue started to happen after I upgraded my mainboard to Biostar TB360-BTC Pro 2.0.
I’m somewhat aware and experienced about gpu driver error, gpu dead etc. errors, mostly this errors caused by OC settings and/or riser cards/cables etc. but the error I need to solve is this “not powering on” issue.