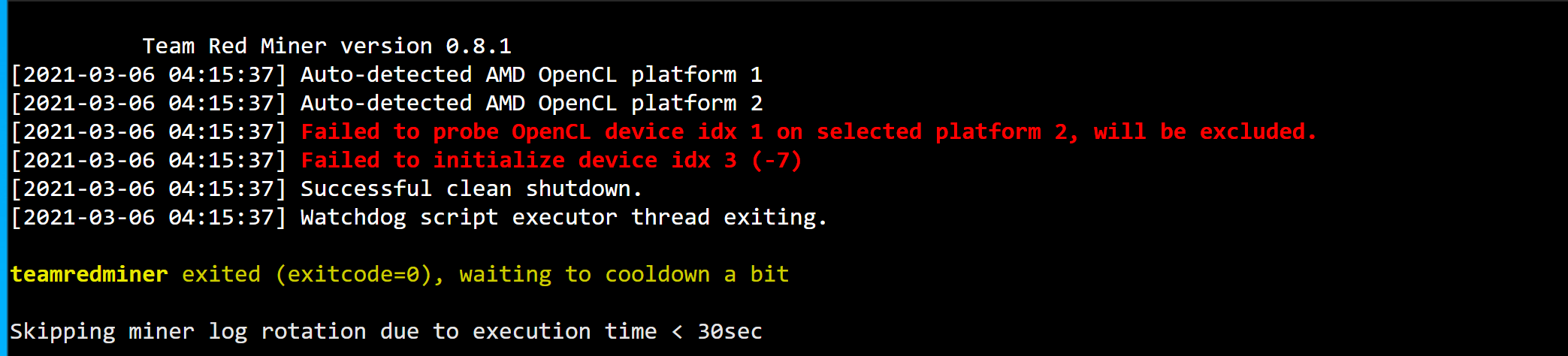
hello, since yesterday I change windows for HiveOS and I’m very happy with it but I get a few errors with my GPU 3. I get 1 or 2 crashes in an hour and always the same error message: Claymore Reboot: WATCHDOG: GPU 3 hangs in OpenCL call, exit
I have tried to change riser nothing change, I have set 0 Overclock the same issue. I have tried to flash an other BIOS and always the same, sometimes it keep mining longer than before, but always after 1-2 hour it will crash again beacause of my GPU 3. I let your le message error here:
=== Last 50 lines of /hive/claymore106/lastrun_reboot.log ===
04:58:16:830 5cff9700 parse packet: 36
04:58:16:830 5cff9700 DCR: Share accepted (245 ms)!
04:58:16:830 5cff9700 new buf size: 0
04:58:17:128 5cff9700 got 402 bytes
04:58:17:128 5cff9700 buf: {“id”:null,“method”:“mining.notify”,“params”:[“b36f”,“07a6c10fa1ea7f96a927d48f9f3a0d7eca18a5679deda9550000002300000000”,“d0fe3e6185253ab86e9bca246b9fbb97e8064a029821ac6b8dd0cd0bbcc9cc65884722e734dd93749c851266965756826ef208293a70aade98ef95bb30edeae201004d99aa1ca16305000c004fa000006e1545191b8fefd101000000b72c0300dd270000d89b6e5a0000000000000000”,“05000000”,[],“05000000”,“1945156e”,“5a6e9bd8”,false]}
04:58:17:128 5cff9700 parse packet: 401
04:58:17:129 5cff9700 new buf size: 0
04:58:17:129 5cff9700 DCR: 01/29/18-04:58:17 - New job from dcr.suprnova.cc:3252
04:58:17:129 5cff9700 target: 0x000000001b6b2f72 (diff: 40GH), block #208055
04:58:17:518 667fc700 DCR: put share nonce 2ee95bd enonce 4c6a000f
04:58:17:518 667fc700 DCR round found 1 shares
04:58:17:519 5cff9700 DCR: 01/29/18-04:58:17 - SHARE FOUND - (GPU 1)
04:58:17:519 5cff9700 send: {“params”: [“marcopollo68.marcminer01”, “b36f”, “94a885624c6a000f75324c6f”, “5a6e9bd8”, “bd95ee02”], “id”: 11, “method”: “mining.submit”}
04:58:18:291 5cff9700 got 37 bytes
04:58:18:291 5cff9700 buf: {“id”:11,“result”:true,“error”:null}
04:58:18:291 5cff9700 parse packet: 36
04:58:18:291 5cff9700 DCR: Share accepted (772 ms)!
04:58:18:291 5cff9700 new buf size: 0
04:58:18:724 88c92700 GPU 0 temp = 67, old fan speed = 22, new fan speed = 25
04:58:18:724 88c92700 GPU 1 temp = 64, old fan speed = 22, new fan speed = 25
04:58:18:724 88c92700 GPU 2 temp = 63, old fan speed = 22, new fan speed = 25
04:58:18:724 88c92700 GPU 3 temp = 56, old fan speed = 22, new fan speed = 25
04:58:18:725 88c92700 GPU 4 temp = 60, old fan speed = 22, new fan speed = 25
04:58:18:725 88c92700 GPU 5 temp = 62, old fan speed = 22, new fan speed = 25
04:58:18:725 88c92700 GPU0 t=67C fan=22%%, GPU1 t=64C fan=22%%, GPU2 t=63C fan=22%%, GPU3 t=56C fan=22%%, GPU4 t=60C fan=22%%, GPU5 t=62C fan=22%%
04:58:18:734 37fff700 srv_thr cnt: 1, IP: 127.0.0.1
04:58:18:734 37fff700 recv: 51
04:58:18:734 37fff700 srv pck: 50
04:58:18:734 37fff700 srv bs: 0
04:58:18:734 37fff700 sent: 263
04:58:20:736 89493700 em hbt: 0, dm hbt: 0, fm hbt: 91,
04:58:20:736 89493700 watchdog - thread 0 (gpu0), hb time 140
04:58:20:736 89493700 watchdog - thread 1 (gpu0), hb time 69
04:58:20:736 89493700 watchdog - thread 2 (gpu1), hb time 69
04:58:20:736 89493700 watchdog - thread 3 (gpu1), hb time 143
04:58:20:736 89493700 watchdog - thread 4 (gpu2), hb time 1
04:58:20:736 89493700 watchdog - thread 5 (gpu2), hb time 73
04:58:20:736 89493700 watchdog - thread 6 (gpu3), hb time 86871
04:58:20:736 89493700 WATCHDOG: GPU 3 hangs in OpenCL call, exit
04:58:20:736 89493700 watchdog - thread 7 (gpu3), hb time 86946
04:58:20:736 89493700 WATCHDOG: GPU 3 hangs in OpenCL call, exit
04:58:20:736 89493700 watchdog - thread 8 (gpu4), hb time 69
04:58:20:736 89493700 watchdog - thread 9 (gpu4), hb time 139
04:58:20:736 89493700 watchdog - thread 10 (gpu5), hb time 46
04:58:20:736 89493700 watchdog - thread 11 (gpu5), hb time 116
04:58:20:736 89493700 Rebooting
I hope some one can help me thanks.