I’ve created small script which makes hiveos image usable, does small clean up and improves security.: HiveOS fix - Pastebin.com
Maybe it will be useful for others too.

I’ve created small script which makes hiveos image usable, does small clean up and improves security.: HiveOS fix - Pastebin.com
Maybe it will be useful for others too.
Even AMD GPUs won’t work without fixing the image. So just create your image and it will work, setup tftp with ipxe on it, add it into your dhcp server and setup any http server to load boot config and other files. It will work with any linux.
Hello everyone, I want to report a serious bug. The diskless installation of hiveos is problematic. I have
tested it many times in the last few days and installed it according to the latest tutorial. After the client
gets the ip, there will be a tftp error and the startup file cannot be found. But according to an old video
client of youtube, it can be started normally without a disk. Although it can connect to the hiveose server
after startup, the client cannot load the nvidia graphics driver and cannot mine at all! ! !
Has hiveos strictly tested your diskless installation tutorial? Maybe there are very few who have diskless
demand like me! : ( 
AMD driver is still 18.40
Track changes here:
Any chance of booting from Network UEFI? Unfortunately some of my rigs only have Network UEFI boot. Was just curious if it was on the roadmap.
Hey Alpha,
I did not have the same problems as you, if you enable TFTP on the dnsmasq you need to disable the Atftpd service that is installed which is what is used for tftp. What version of ubuntu are you running? Here is my version: Ubuntu 18.04.5 LTS that seems to work well. The only change I needed to make was adding the resolv.conf. I am running this off of libvirt but I did also get it working on virtualbox.
The reason dnsmasq is not serving leases is because it is working as a proxy to your main dhcp server which is you router I presume which you can see in the config file located at: /etc/dnsmasq.conf
Also make sure your VM is in promiscuous mode for your network adapter on a bridged connection.
You can try a sudo netstat -nap | grep 69 to see what program is currently running on port 69 and see if you can stop it or if it’s a service you need.
Check out the atftpd config, is it pointing to the right directory? cat /etc/default/atftpd should tell you near the end of the file.
What miners have been tested with the Nvidia drivers? I have been able to mine ubiq with phoenixminer but not able to mine RVN with NBMiner. Below is the error in the miner log file.
[14:41:44] ERROR - CUDA Error: PTX JIT compiler library not found (err_no=221)
[14:41:44] ERROR - Device 8 exception, exit …
[14:41:44] ERROR - CUDA Error: PTX JIT compiler library not found (err_no=221)
[14:41:44] ERROR - Device 11 exception, exit …
free(): corrupted unsorted chunks
[14:41:45] ERROR - !!!
[14:41:45] ERROR - Mining program unexpected exit.
[14:41:45] ERROR - Code: 11, Reason: Process crashed
[14:41:45] ERROR - Restart miner after 10 secs …
[14:41:45] ERROR - !!!
I was able to get past this error by installing the nvidia-cuda-toolkit to the image.
apt install nvidia-cuda-toolkit -y
Is there anyway to enable Nvidia with PXE? We have around 600 rigs that use Nvidia cards (mostly p106) and we want to move to net boot for stablity.
Current version appears to have an issue booting out of the box… seems to be an issue in initrd-ram.img:/scripts/nfs where $fs_size is calculated and passed in the pipe to ps on line 73 & 74.
I’m currently testing 100% virtual before I roll this out to a production rig for testing - I see the client pull the file from the nginx server but it fails with an error.
Download and extract FS to RAM
pve: option requires an argument – ‘s’
Try `pv --help’ for more information.
xz: (stdin): File format not recognized
tar: Child returned status 1
tar: Error is not recoverable: exiting now
Which then results in a cascade of failures on boot. I never see the client request the tar.xz file from the nginx daemon according to logs.
I’ve tried fixing the error by unpacking the initrd-ram.img file, editing the file, and repacking. I’m new to PXE and manipulating the initrd image so I may not be packaging the .img file correctly seem to indicate the img is not being extracted properly by the client.
Any pointers would be much appreciated.
UPDATE and SOLVED:
I managed to solve the issue. It was definitely a problem on my end dealing with virutalization. I realize this is a fringe case as I am using a virtualized client for testing and won’t be using virtualized clients for production but I’m going to post my causality anyway in case anyone else is running into this issue.
I’ve managed to get the image file repacked properly. For anyone wondering how to do that the command I used which appears to work is: find . | cpio -H newc -o | gzip -9 > ~/initrd-ram.img
The issue appears to be with line 73 in /scripts/nfs which is:
fs_size=$(/bin/wget --spider ${httproot}${hive_fs_arch} 2>&1 | grep “Length” | awk ‘{print $2}’)
Debugging I tried to echo the value of fs_size which returned a null value… so the above is defunct likely due to some output format changing from wget. So I threw in a few debug commands surrounding line 73 to show the output of /bin/wget --help and /bin/ip link…
It turns out that the initrd image wasn’t able to load the driver for the virtIO network interface emulated by proxmox… so switching the VM’s network interface card model to Intel E1000 fixed the issue.
А как-то можно обновить сервер на определенную версию именно образ системы? чтоб не последний а который нужно
The 2021-08-12 update does not write/create /etc/dnsmasq.conf properly.
It will have a section which says that the server IP address is 192.168.1.230 even if you set it to something other than that.
At the end of running pxe-setup.sh it will say:
Restart DNSMASQ server. Job for dnsmasq.service failed because the control process exited with error code.
See “systemctl status dnsmasq.service” and “journalctl -xe” for details.
Thanks.
edit
Update:
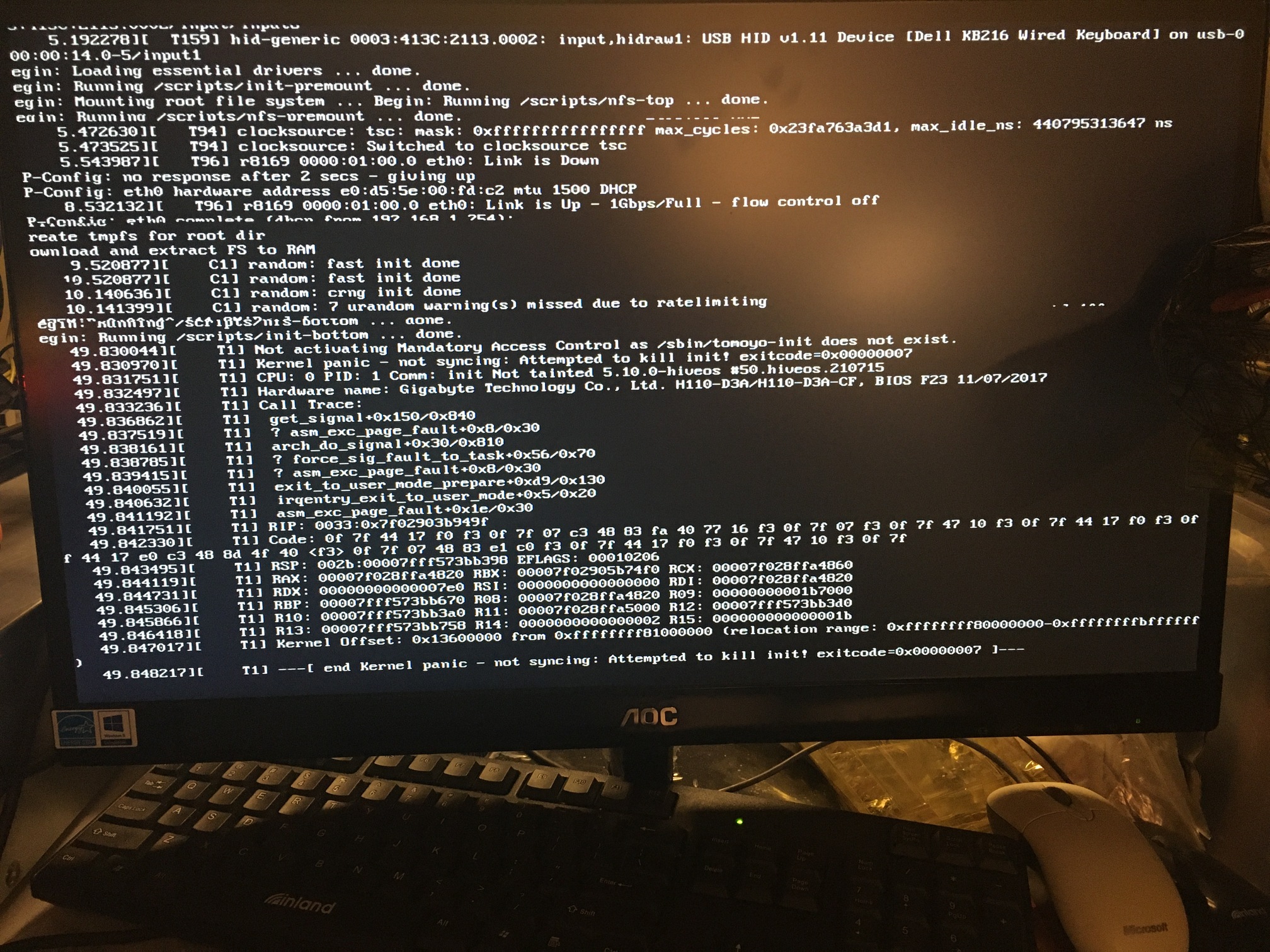
New master causes a kernel panic.
Not sure about the root cause.
Thanks.
edit
Here is the screenshot of the kernel panic when it tries to boot off the updated server and hiveramfs image:
The same happens even after you run sudo ./hive-upgrade.sh.
I can also confirm that if I DON’T upgrade the PXE server, the kernel panic doesn’t happen, even if I update the hiveramfs image.
But if I update both the PXE server image AND the hiveramfs image, then the kernel panic DEFINITELY will happen.
Hello
I had exactly the same case.
Did you manage to solve this problem?
Exact same issu here… Staff will make an update soon ?
We can’t make a fresh install working 
@david1
I “solved” this issue because I had made a backup of the entire PXE server install directory before performing the upgrade to the PXE server, so I just restored from that backup and that was how I “fixed”/“solved” the issue.
It is rather unfortunate because I am not a programmer and I don’t really understand code when I read it (or even shell scripts for that matter), so I can’t even begin to remotely pin-point the source nor the root cause of the problem.
If I didn’t have my backup copy of the folder before performing the upgrade, I’m pretty sure that I’d be screwed and that I would need to use the disk image to bring the system back online until the PXE server update could be fixed so as to NOT cause a kernel panic.
It’s also a pity that the PXE server update DOESN’T automatically ask you if you want to backup your server first BEFORE running the upgrade, even if running the backup make take a while (it depends A LOT on how many files you have in your backup_fs folder.)
But yeah, that was the only way that I was able to “restore” or “fix” my system, was to restore from backup that I had made a while ago before I ran this PXE server update.
Hello. We have same problem here. First time using this method then no save or backup available…
Are you OK to share your backup folder with your farm config hide?
Thanks in advance for sharing @alpha754293 
Let me see what I can do about that.
I’ll have to figure out all of the various places where information specific to my setup/configuration is stored and I’ll have to figure out how to strip all of that information out from it as well.
In addition to that, the current state of my backup file right now is about 7.3 GB in size (which will likely be a bit too large for people to be able to download in a reasonable and/or sensible fashion), so I’ll have to delete some of the backups from the backup_fs folder to make it smaller and more portable for people to download and use as a way to restore their PXE server as the current and temporary fix to this kernel panic issue, unless someone knows of a way to unpack it and maybe patch the kernel that they’re using or whatever might be the root cause/issue that’s causing said kernel panic.
Either way, let me see what I can do.
I’ll also have to figure out a way to publish the file (e.g. a site or location where I can publish a multi-GB 7-zip file). (If people have suggestions, I’ll gladly entertain them/take a look at those said suggestions.)
Thanks.
edit
Here is the link to the file, which I’ll host on my Google drive for about a week:
https://drive.google.com/file/d/1sZmf2hgC_vp_ohA4V2WMHQpDBxpKa7Kc/view?usp=sharing
SHA256:
e6032a7b43e8cccfc6c2aec76ee9c1d21d7ea3de2261d2a7097821ccebc8b8b8
Total file size:
1,439,864,662 bytes
I think that I stripped out all of my own personal, config-specifc information out from there, so it should be sanitized now.
You will need to download 7-zip/p7zip for your system/distro and I trust that you guys can figure out how to do that for your specific installation/distro/etc. (Google it.)
I would recommend that you download it and extract it on your Desktop (e.g. ~/Desktop) for your OS and then you can move the files to wherever they need to go for your specific installation.
You SHOULD be able to overwrite your existing files (which is causing the kernel panic anyways), but if you want to be safe, you can always backup your files (7-zip/p7zip is GREAT for that) before moving the files from my archive/backup and overwriting your own files.
Once you’ve confirmed that you are able to get your PXE server back up and running, then you can probably safely delete the bad copy of the PXE server files anyways.
Also, I will note for everybody here that after you download and extract the files, and you move them to where they need to go – you WILL need to run pxe-config.sh again to set up your farm hash, PXE server IP address, and anything else that you might need to setup/re-configure.
The server should be as recent as 2021-07-30, at which point, you can run sudo ./hive-upgrade.sh and when it asks you if you want to update the PXE server, select No and you should be able to proceed with upgrading the OS itself without upgrading the software that runs the PXE server itself.
I will also recommend that you check the dnsmasq.conf file because I also found that when I ran the hive-upgrade.sh multiple times, it will append the settings to your /etc/dnsmasq.conf multiple times. So, you might have to also go in there and make sure that’s cleaned up as well. (Not sure WHY it’s doing that, but it was just a behaviour that I observed that has popped up recently.)
Last but not least, also before you reboot your mining rigs, you’ll also want to make sure that atftpd, nginx, and dnsmasq servers/services are running properly by checking their status with sudo systemctl status and make sure that there aren’t any issues with any of those services otherwise, your mining rig may not work.
For example, because I had the issues where hive-upgrade.sh apparently seemed to keep appending to my /etc/dnsmasq.conf file, so when I rebooted my mining rig, it would say something like either it can’t pick up whatever dnsmasq is serving (my DHCP is managed by something else). Or another issue that I found was that if the atftpd service wasn’t running properly because there was a port 69 conflict with dnsmasq, (run sudo lsof -i -P -n | grep :69 to check for that), the mining rig wasn’t able to pick up the PXE boot file from the atftpd server (it will say something like PXE boot file not found or something along those lines).
So you’ll also want to check and make sure that’s up and running properly as well.
(You can also use sudo lsof -i -P -n | grep atftpd and ... | grep dnsmasq as well to see which ports those services are actually using. On my system, atftpd wasn’t listed (the service exited, but it doesn’t seem to be having an issue running, so [shrug] - I dunno - it appears to working. I’m not going to mess with it. My rig boots up and to me, that’s all that matters. dnsmasq appears to be using port 69.)
So yeah, check that to make sure that it is all up and running and in good, working order and then, go ahead and try and reboot/start your mining rig(s).
These are the issues that I’ve found when I was trying to run this most recent update (that it caused).
Your mileage may vary and you might encounter other problems that I haven’t written about here, so hopefully, things will work out for you and your specific installation/set up.
Again, I WILL say though, HiveOS’ diskless PXE boot IS really cool and nifty. There are still other issues with it, but for what it’s worth, I STILL do find it useful despite those other issues.