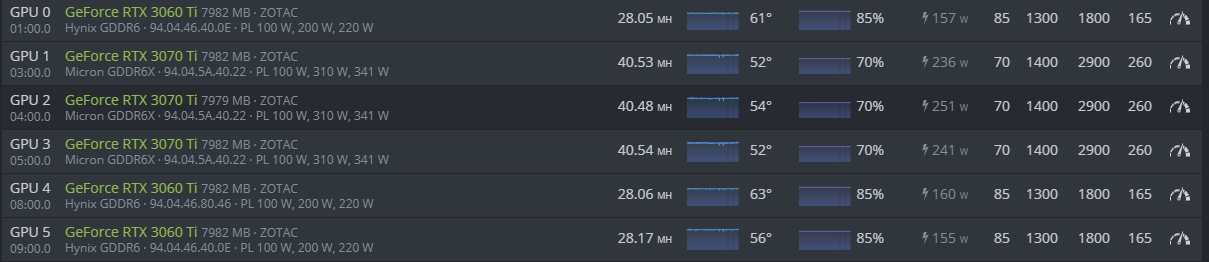
I have 3x Zotac 3070 ti’s and 3x Zotac 3060 ti’s LHR
This is a new build, my 3rd HiveOS rig, 2 other rigs mine Ethereum.
This is for Raven coin. I
I keep getting
GPU driver error, no temps
and
LA > 22 rebooting
I moved my OS to SSD drive but same issues, but now I am running stable I think because I cleared out overclocks and just am power limiting cards to 150 for 3060 ti and 250 for 3070 ti
What is anybody’s recommend setting for these cards on Raven?
Hi there. Here are my settings on a single 3060ti and a 3070ti. I have 2 3070’s and they perform a little different
3060ti: 27mH. Mem 2200, power 160
3070ti (reference): 39.5mH. Mem 2100, power 240
3070ti (EVGA FTW3): 38.5mH. Mem 2200, power 250. This card doesnt run as good as the reference card, which was the opposite of how I thought it would work.
you got fucked over with 3060ti’s hynix memory, i get max 27.5mh with +50core , 550 memory before crashing every 5mins, whereas my samsung ones get 32+ stable
I was stable with these setting for a few days then I started crashing again. Card 3 (3070 ti) would not mine so I removed it out of the system to see if the system would run stable. It did for about a day now its crashing again. Is the Load Average error because of over clock settings or is it hardware related?
Yeah, I’ve thought about using a different miner. Clearly you see I am on t-rex and nanopool. Maybe I just leave it alone. Was on Gminer late last week and had about the same results
It’s not only with NBMiner, I have the same issue on T-Rex miner. The thing is I’m not sure it came from 3060ti Hynix memory or 3070Ti Micron memory. Is there anyway we can pinpoint which GPU is causing the error no temps, auto fan error etc?
start by dropping all 3070Ti’s memory and core to 0. And then work on the overclocks one card at a time. this is what I have been doing.
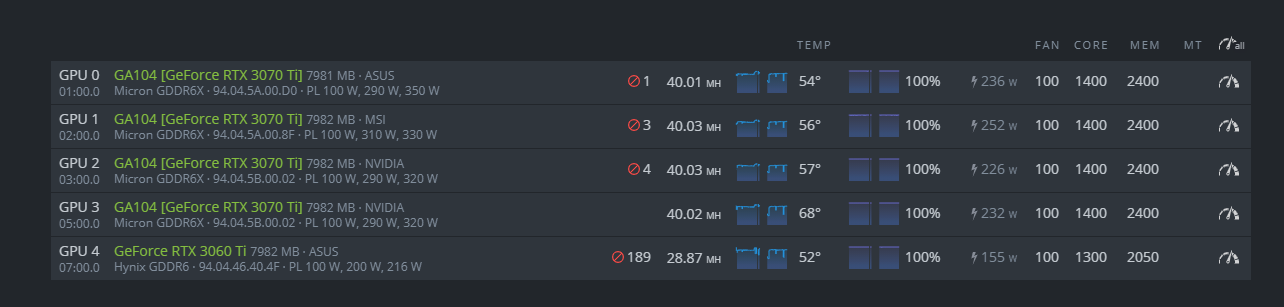
I have 3x 3070Ti’s and started with the GA104 error every time i added a 3070 Ti so I had to update drivers to 2 different drivers withe the miner stopped.
When I got that over I had the Temps/stats issue so that’s when i dropped my clocks to 0 core, 1500 memory with 250 pl and 85% fan.
All 3 are ASUS TUF 3070 Ti’s with Micron Memory but when i bump the memory to 2000 on the first two i get the Temp/Stat glitch.
Same thing happens when bumping the core anything more than 300 on the first two.
All 3 cards work the same at 0 and 100 core but anything other than that they don’t like it.
Ps. I have also use 250 pl and always below 60 degrees Celsius to make sure it’s not a over-heating issue or not enough power.
I would like some help though myself fine tuning these cards to 39+ MH/s on RVN
Also I would like to know if the intensity could play a role here with T-Rex Miner as it’s at 20 intensity for all 3.
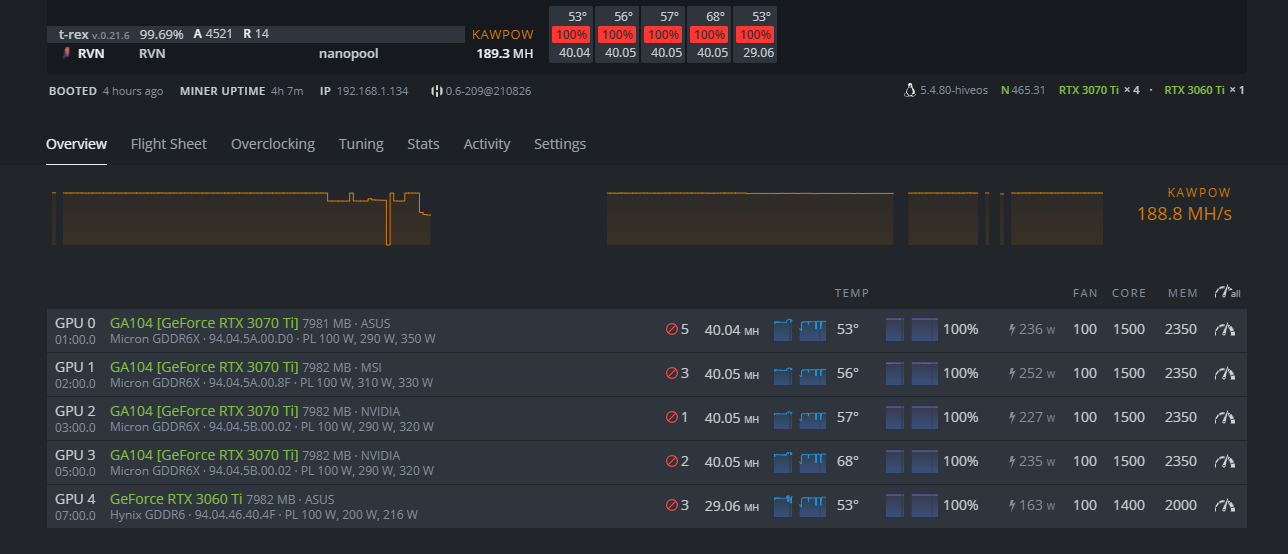
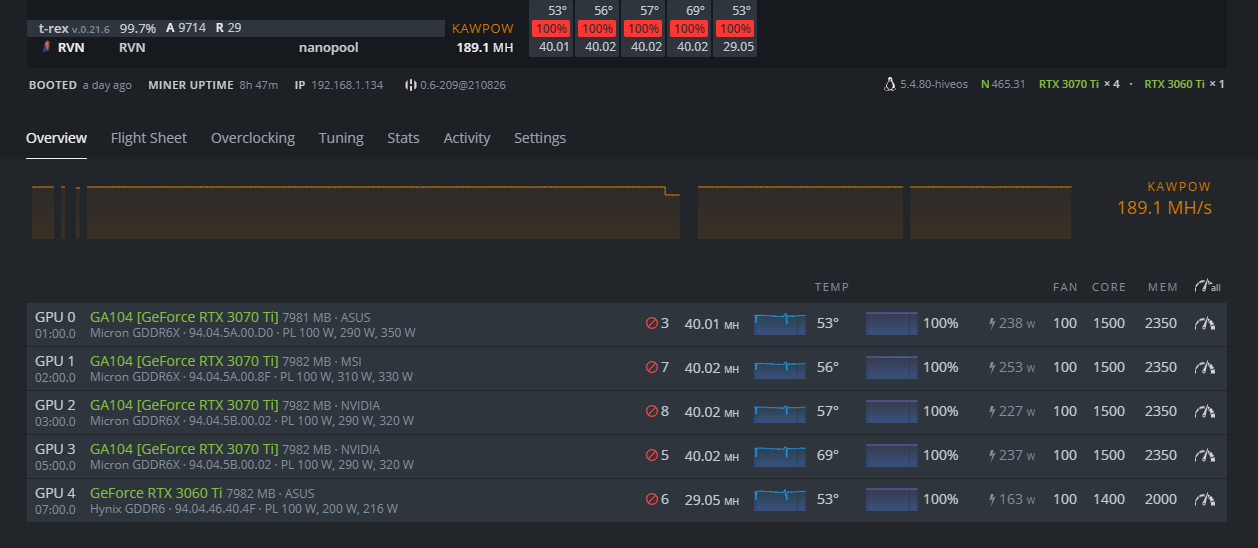
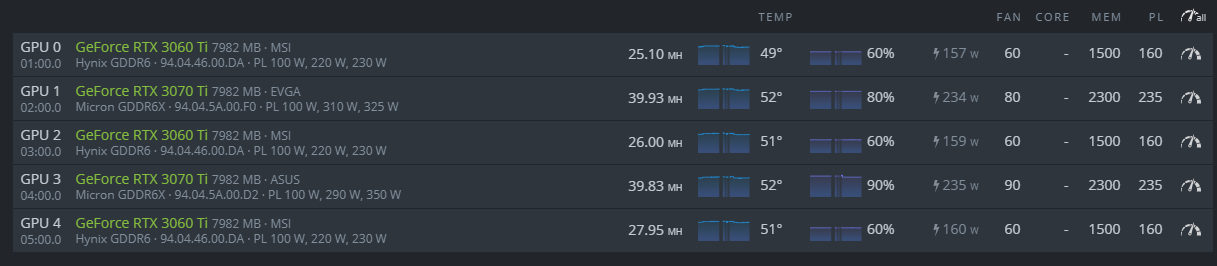
This is where I’m at now. (GPU3 is ASUS TUF, GPU1 is EVGA ftw3) I’m doing the same thing as you but on the opposite, i’m working my way down from 3070ti memory clock 2700. I found that PL 235 is a sweet spot to keep the temperature under control. Also my observation is when the GPU temp is more than 56-57, my ASUS TUF will went crazy and crash the whole rig with error “error no temp”. Also if PL is less than 235, the hashrate will be fluctuated a lot.
If memory 2300 is still not stable, I will reduce it further. to 2250.
Do you think core clock does improve the hash rate? I don’t see much improve so I leave it.
I think the card gets slightly hotter with core at 100 and there is a slight drop 0.02 MH difference. Very small difference. 0 core being better.
I’m steady now for a few days at 2000 memory on one of my Asus TUF 3070 Ti’s.
The other two are at 1650 memory due to having no space between them and I have heat issue I think. Wish I could see Core temp or any way to see if they are thermal-throttling.
I see your temps are much better than my temps. What frame are they on? Do you have a big space between them? What is your ambient temp? Are you steady at 2300?